
RDBMSを運用していて一番困るのは、データベースの性能が低下し、適切なパフォーマンスが出せなくなったときです。
サーバーのCPU負荷はみるみる上昇し、そのデータベースを参照しているあらゆるアプリケーションやシステムの処理は遅延し、動作も不安定になっていきます。
明らかにデータベースがおかしいと判断した場合、その原因箇所を切り分けて特定する必要がありますが、データベースの性能低下には様々な可能性が考えられます。
このようなトラブルシューティングでは、データベースに対する相応の知識と経験が必要です。
今回の記事では、経験の浅いDB管理者向けとして、一般的なRDBMSにおいて、処理が極端に遅くなるなどの性能低下が起こった場合に考えられる原因を色々と紹介しつつ、その対応方法についても簡単に解説していきます。
トラブルシューティングにおいて大事なのは、原因の可能性をいくつ列挙できるかです。
より多く思い付くことができれば、そのなかのどれかが本因である可能性が高く、思い付いた原因をひとつひとつ検証していけば、必ずトラブルは収束できます。
この記事がその手助けになれば幸いです。
長い記事ですが、これでも最低限知っておいてほしい内容に要約したつもりです。
是非頑張って完読してください!
データベースが遅くなる原因例とその対策
当項では、一般的なRDBMSにおいて、パフォーマンスが低下し、クエリの応答が遅くなった場合に疑うべき様々な原因の例を紹介していきます。
また、個々の原因例に対して、一般的にはどのように対応するべきかについても簡単に解説していきます。
統計情報の破損や実態データとの乖離による原因
通常のRDBMSでは、クライアントから入力されてきたり渡されてきたSQLの指示内容に従い、自インスタンス内のデータベースを参照して目的の行をクライアントに返したり、指示されたデータの更新や追加などを行います。
RDBMSがクライアントから渡されたSQLを元にSELECTやUPDATEなどの処理を実行する一連の流れとしては以下になります。
- 渡されたSQLの構文を解析
- 解析結果を元に、統計情報を踏まえて処理の最適化を実施
- 最適化内容を元に、実行可能な形式にコンパイル
- 処理を実行
これらの一連のプロセスは、RDBMS内の「オプティマイザ」と呼ばれる機能が担当しており、このオプティマイザの「賢さ」がそのRDBMSの性能を決めるといっても差支えはありません。
このオプティマイザは渡されてきたSQLを解析し、統計情報を参考にして処理の最適化を行います。
「統計情報」とは、各テーブル内の行数やインデックス項目の値の分布状態、値の個数など、処理の最適化に必要な情報です。
この統計情報はリアルタイムで都度算出されるものではなく、テーブルを作成したタイミングや、インデックスを作成したタイミングなど、特定のタイミングで算出した時点情報です。
オプティマイザはこの「統計情報」を元に、SQLで指示された処理を最も効率的な内部処理に置き換えて、実行可能な形式にコンパイルします。
オプティマイザが人の脳と例えるなら、「統計情報」はその人の知識です。
賢い頭脳があっても、持っている知識が間違っていたり、現在の状態と乖離した古い知識であった場合は、正しい解答を導き出せません。
よって、この「統計情報」はデータベースのパフォーマンスを適切に保つにあたり、非常に重要な役割になります。
この統計情報が何らかの理由で破損したり、テーブル内の実際のデータと極端に乖離することで、データベースのパフォーマンスは大きく低下します。
詳しくは、以前に当ブログで記事にした以下のリンク先をご参照ください。

尚、データベースが遅い原因が「統計情報」にある場合、データベース全体で遅延が起こるケースはあまりなく、特定のテーブルを参照した場合や特定のインデックスを参照した場合、特定のストアドプロシージャを実行した場合など、局所的、且つ顕著なレスポンス低下が起こるケースが大半です。
そのような特徴の性能低下がデータベースで確認できた場合は、「統計情報」を疑ってみましょう。
統計情報の異常が原因だった場合の対応方法
統計情報が原因である可能性が高い場合、性能低下を起こしているクエリやストアドプロシージャを可能なかぎり特定します。
対象のクエリが特定ができれば、次は実行しているクエリを更に分解し、どのテーブルを参照する処理が遅いのかを調査します。
尚、統計情報自体は各テーブルの各列ごとに情報を保持しているため、さらに列単位でおかしくなった統計情報を特定することも可能ですが、極端に巨大なテーブルでなければ、対象のテーブルまで特定できれば十分です。
統計情報は、RDBMS毎に用意されている統計情報更新用のコマンドを手動で実行することにより、現在のテーブルの実データを元に統計情報を更新することができます。
統計情報の更新コマンドでは幾つかのオプションが指定でき、それによって、テーブルの全行を対象に解析するか、特定の行をサンプリングして解析するかなどの指定ができます。
詳しいオプションの説明は、RDBMSごとに提供されている公式の技術資料をご確認ください。
正しい統計情報が再度作成されれば、発生していたデータベースの遅延は一気に解消することが大半です。
必ず覚えておいてください。
ロック待ちやデッドロックによる原因
一般的なデータベースにおいて、データの信頼性を担保する仕組みとして欠かせないのが「排他制御」です。
特定のレコードに対して同時に複数の更新指示が行われた場合に、データベースは先着順で処理を受け付け、後から来たリクエストは前の更新処理が終わるまで処理を待機させる仕組みです。
この処理を待機させる仕組みを「ロック」と呼びます。
また、対象のRDBMSのロック制御の仕様によっては、更新処理だけではなく、更新処理中の未確定状態にあるレコードを参照しようとした場合にもロックは発生します。
データベースが適切に排他制御を行うことで、データが不正な値で更新されてしまうことを防ぎ、確定された正しい値を参照させています。
この排他制御は一般的なデータベースにおいて欠かせない仕組みですが、このロックに起因した「待機」時間が積み重なると、それはデータベースの処理遅延に繋がります。
このロックはレコード単位だけではなく、複数のレコード格納ディスク領域である「ページ」単位や、テーブル単位、データベース単位で適用することもできます。
RDBMSの製品によっては、テーブルの更新対象範囲やロックの発生状況により、レコード単位ではなく、ページ単位やテーブル単位などロックの精度を自動的に広げてしまう機能(ロックのエスカレーション)も存在し、ロック精度が広がるほど待機させられるプロセスも増加します。
また、異なるプロセス同士が同じレコードに対してお互いにロックを掛けてしまい、互いに相手の処理が終わるのを待ち続ける現象が起こる場合もあり、この現象を「デッドロック」と呼びます。
尚、データベースにおける「ロック」の仕組みや詳細な解説については、過去に当ブログで記事にしておりますため、良ければ以下のリンク先もご一読ください。
ロックに起因したデータベースの性能低下の厄介なところは、アプリケーションのテスト段階では問題が露呈し難く、アプリケーションを本番環境で動かして始めてその現象が確認できるようになる点です。
また、アプリケーションのリリース初期段階では問題が無くても、アプリケーションをリリースして時間が経過し、そのアプリケーションを利用するユーザーが増えたり、格納されるデータ量が増えることで顕著にその症状が頻発するようになるなど、時限性を持った症状である場合も多く、そこも未然に防ぐことが難しい事象だと言えます。
尚、データベースでは大量のリクエストを受け付け、多段的に発生するロックプロセスを適切に管理する処理は負荷の高い行為です。
そのため、ロック待ちの増加はデータベースサーバーのCPU負荷の増加につながります。
ロックやデッドロックが原因だった場合の対応方法
SQL ServerやOracleなどの各RDBMS製品ごとに、データベースの状態をモニタリングするGUIツールやCUIコマンドが用意されており、そのツールなどを活用することで、データベース内のロック状況を確認することが可能です。
対象のデータベースに対して、現在ロックしているプロセスの数、対象のプロセスID、個々のプロセスの実行時間(待ち時間)、個々のプロセスの状態、プロセスが実行している(実行予定の)SQL内容など様々な情報を得ることができ、その情報を元に、長時間ロックし続けているプロセスを探したり、現在のロック待ちプロセスの数から適性な状態か否かの判断材料とします。
そのような調査の結果、ロックが大量に発生していることがデータベースの性能低下の原因と考えられる場合は、そのロックを発生させている更なる原因を調べます。
極端なロックプロセスの増加が起こる可能性のあるケースとしては以下です。
- アプリケーションの実装上の問題
- データベース自体のパフォーマンス低下
- 新しいシステムやクライアントの追加
データベースを使用するアプリケーション側の実装が適切ではないことで、ロックプロセスを増加させてしまう場合もあります。
アプリケーション側では複数の更新処理をまとめて実行する場合、「トランザクション管理」の仕組みを利用します。
例えば、売上伝票データにおける「ヘッダデータ」と「明細データ」のように、テーブルAとテーブルBをまとめて更新する場合、テーブルAの更新に成功し、テーブルBの更新に失敗するとデータに不整合が起こります。
それを防ぐために、アプリケーション側では更新処理を開始する前に、「トランザクション開始」を宣言します。
その後テーブルAを更新し、テーブルBを更新して両方の更新処理に成功した場合のみ、更新結果をテーブルに反映させます。
その反映処理を「コミット」と呼び、トランザクション開始の宣言をした場合、アプリケーション側で明示的に「コミット」指示を出さないと、その更新結果は実テーブルには反映されません。
もし、テーブルAの更新に成功し、テーブルBの更新に失敗した場合、アプリケーション側ではその失敗を検出できるようにしておき、テーブルAの更新自体もなかったことにします。
それを「ロールバック」と呼びます。
この「トランザクション管理」の仕組みを利用して、アプリケーションではデータの整合性を担保しているのですが、アプリケーション側の実装が甘く、ロックする必要のないレコードまでロック対象を広げてトランザクションを掛けているようなケースもあります。
また、プログラムの実装を工夫することで、より短時間で更新処理が終わるようにして、更新プロセスがロックする時間を短くすることもできる場合があります。
前述した「デッドロック」においても、テーブルAとテーブルBを同時に更新する際に、アプリケーションAは「テーブルA→テーブルB」の順番に更新を行い、アプリケーションBでは「テーブルB→テーブルA」の順番で更新を行っていた場合、アプリケーションAとBが同じデータを同タイミングで更新を掛けることでデッドロックが発生します。
これは、アプリケーションごとに、テーブルAとBの更新順が決められていないことにより、デッドロックを誘発させていると言えます。
よって、テーブルAとBを更新する場合は、必ずテーブルAから更新するとルール決めをすることで、デッドロックの回避が可能です
これらのように、アプリケーションの実装上の問題によってロックを誘発している場合、その実装方法を見直すことで現象が改善される可能性は十分あります。
データベース自体のパフォーマンスが低下していることで、ロックプロセスを増加させてしまう場合もあります。
クエリの応答速度が低下したことにより、更新処理に時間が掛かるようになり、その結果ロック待ちプロセスが増加してアプリケーションの動作が不安定になるといったケースも考えられます。
当項における「データベース自体のパフォーマンス低下」とは、前述した「統計情報」の影響によるものや、後述するインデックスの断片化によるものなど、クライアントやアプリケーション側ではなく、データベース側に問題があるケースを指しています。
データベースのデータを更新する場合、テーブルの全行を一気に更新するようなことはあまり行いません。
通常はSQLのUPDATE文にWHERE句を付けて、更新するレコードを絞り込んだうえで更新します。
また、アプリケーションの実装方法によっては、一つのトランザクションのなかで繰り返し更新処理を実行し、更新された行はコミットされるまでロックされた状態になります。
そのため、更新対象の絞り込みに時間が掛かってしまうと、トランザクションの開始からコミットまでより時間が掛かるようになり、その結果、データベース全体のロックプロセスが増加し、データベース全体のパフォーマンスや安定性に影響がでるようになります。
よって、データベース自体のパフォーマンス低下がロックの増加要因になっていると判断された場合は、前述した統計情報のメンテンナンスを実施したり、後述するインデックスのメンテナンスを行い、データベースが良好な性能を維持できるようにしてあげる必要があります。
データベースを利用するアプリケーションやシステムの増えたり、これまで存在しなかったクライアントが追加されたことをきっかけにロックプロセスが増加するという場合もあります。
データベースを利用するアプリケーションやシステムが増えたり、新しいクライアントが増えた場合、新しいシステムやクライアントの規模によっては、データベースに対するアクセス自体が一気に増えます。
アクセスが増えれば、データベースサーバーの負荷も増加し、データベースが処理していたクエリの応答速度も低下することになり、その結果、ロック待ちプロセスが増加することが考えられます。
また、新しいシステムの追加だけではなく、既存システムに対して改修を行った場合でも、それによってこれまでとデータの取り方やアクセス頻度が変わり、データベースの負荷が増加するようなケースもあります。
例えば、とあるシステムでは夜間のバッチ処理でテーブルの一括更新をしていたが、ユーザーはデータの反映が翌日しか確認できないのが不満だったため、その更新処理を日中のオンライン処理(逐次処理)に変更しました。
その結果、日中の更新処理が一気に増加して、ロック待ちプロセスが大量に発生しだしたというケースもあります。
そのデータベースを利用するシステムが増えたり、クライアントが増えることでロックプロセスが増えてデータベースの性能が低下する場合、そのシステムの実装方法に問題がある場合もありますが、単純にデータベースサーバー自体のハードウェアの性能が足りなくなったという場合も考えられます。
現実的には、データベースの性能低下を理由に新しいシステムの稼働を中止したり、クライアントの追加を断念するといった選択肢を取ることは通常あり得ないため、何らかの対応をして状況を改善させることが必要になります。
インデックスの断片化や不足による原因
一般的なデータベースにおいて、クエリのレスポンスに最も影響を与えるのが「インデックス」です。
「インデックス」を日本語に訳すと「索引」です。
紙の辞書で調べたい言葉があった場合、増大なページ数を1ページ目から順に1枚1枚探していく人はいません。
まず辞書の索引を調べ、索引内で目的の言葉を見つけてから、目的のページを直接開きます。
データベースにおいても同じであり、クライアントからSQLの指示を受けて条件に合うレコードをデータベースが探す場合、インデックスを活用することで、目的のレコードを効率よく見つけ出すことができます。
尚、当ブログでは、過去にデータベース初心者向けの記事を掲載しており、その記事のなかで、「インデックス」についても解説しています。
良ければ以下のリンク先をもご一読ください。

この記事のなかでも解説していますが、このインデックスを適切に利用することで、例えば数千万件のレコード数を持つテーブルであっても、目的のレコードを一瞬で見つけ出すことが可能になります。
但し、このインデックスは、テーブルに対してレコードの追加や削除、値の更新を繰り返していくことで、「断片化」と呼ばれる状態が進行し、利用効率がどんどん低下していきます。
データベースのインデックスにおいて最も基本的な構造である「B-treeインデックス」における断片化について簡単に説明します。
「B-treeインデックス」では、ルートノードを頂点とし、末端のリーフノードにレコードの位置情報が格納され、ルートノードのリーフノードの間には、幾つかの階層を持つブランチノードがあります。
ブランチノードは目的のレコードがどちらの下層ノードに存在するかがわかるようになっており、そのブランチノードを数回辿ることで、リーフノードの辿り着けるようになっています。
これは「二分探索木」と呼ばれる構造です。
この仕組みにより、何十万件のレコードを持つテーブルであっても、インデックス内のノードを何度か参照することで、目的のレコードを瞬時に探し出すことが可能になります。
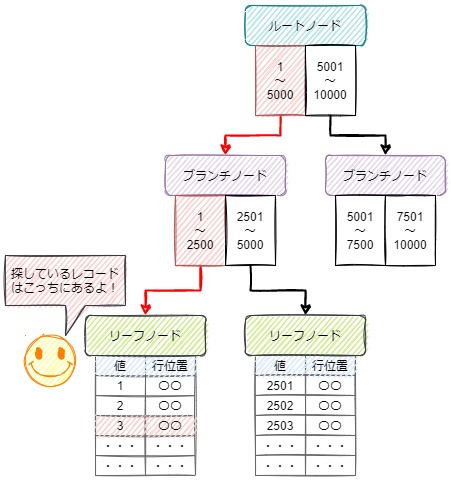
B-treeインデックスが目的のレコードを探すイメージ
この各ノードの内部データは、データを効率よく探せるようにソートされ順番に並んでいますが、レコードの削除により空き領域が発生したり、レコードの追加によってノードの分離が発生します。
また、インデックスが設定された列の値の更新が行われた場合、ノード内のデータの並び替えや再配置が行われます。
それらが繰り返されていくことで、各ノード内の空き領域が増加し、ノードの数が不必要に増えていきます。
ノードが増えていくことで、データを探す場合に参照するノードの数も増えていくことになり、目的のレコードを探す効率が悪化して処理速度の低下に繋がります。
これが「インデックスの断片化」です、
このようなプロセスを経て発生する現象であることから、ある日突然遅くなるようなことはなく、日々のデータベースの使用によって、少しづつ性能が劣化していくケースが大半です。
あと、インデックスに起因した性能低下では、前述したインデックスの断片化だけではなく、本来必要な列にインデックスが設定されていないケースもあります。
インデックスはデータベースが自動的に必要な列に対して作成してくれるものではなく、どの列にインデックスを付与するかをテーブル作成時などで明示的に指定して付与します。
上記の記事にも記載しておりますが、インデックスはすべての列に付与すればよいものでもなく、列ごとの格納される値や、想定する参照のされ方をもとに、必要な列にだけ付与していくものになります。
インデックスを付与するべき列の条件は、大まかに言えば以下になります。
- 検索条件として使用される
- 値の分布が広い、又は一意に近い
- テーブルのレコード件数が多い
インデックスは、対象の列がクエリの検索条件として指定された場合に使用されるデータ領域であり、検索条件として使われることがない列に対してインデックスを付与しても意味がありません。
また、レコードの追加時などは前述したノードの分離が発生し、処理速度の低下要因となるため、インデックスは検索で使用する列にだけ付与します。
インデックスは値が広く分布している列に対して付与します。
例えば、男女の区分を格納する列であれば、値は二つか三つ程度であり、値の分布は非常に小さいと言えます。
この区分を検索条件にしたクエリを実行した場合、1行ずつインデックスから条件に合う値を探すより、テーブルの先頭行から順に走査したほうが早いケースもあります。
インデックスは、レコード件数の多いテーブルの列に対して付与します。
マスタ系テーブルのように、一つのテーブルに数行や数十行しか登録されていない場合は、そのテーブルの列にインデックスを付与することによるメリットは殆どありません。
上記の内容の踏まえつつ、インデックスを付与するべき列にも関わらず、インデックスが付与されていない場合があります。
例えば、アプリケーションやシステムの導入当初は検索条件として使われることのなかった列が、システム改修によって検索条件に後から追加されたケースもあります。
また、アプリケーションやシステムの導入当初はレコード件数が少なく、インデックスが付与されていなくても瞬時に検索できていたが、時間が経過しレコード件数が増えたことで、インデックスの付与が必要になったというケースも考えられます。
これについては、テーブルを設計したSEの考慮不足でもあります。
また、単純にインデックスの付与が漏れていて付与されていない場合もあります。
インデックスが付与されていなくても、データ件数が少ないうちは問題無くデータベースを利用できるため、そのまま設定漏れに気付かないままリリースされてしまうこともあり得ます。
インデックスの断片化や不足が原因だった場合の対応方法
RDBMSの製品ごとに、インデックスの断片化率を調べるためのコマンドやツールが用意されており、それを利用することで、著しく断片化が進行したインデックスを見つけることが可能です。
インデックスの断片化が進行している場合は、以下のどちらかで対応します。
- インデックスの再構築
- インデックスの削除と再作成
「インデックスの再構築」では専用のコマンドを実行します。
コマンドでは再構築する対象のインデックスを個別に指定して実行することも可能ですし、テーブルを指定して、そのテーブル内のインデックスすべてに対して実行すること可能です。
「再構築」の具体的な処理内容はRDBMSによって異なりますが、一般的にはノード内の空き領域が前に詰められ、データは物理的な順番で並ぶように再配置されます。
また、再構築の手法によっては構築処理中でもテーブルをロックすることなく、オンラインで実施することも可能です。
再構築ではインデックスのオブジェクト自体を削除しないため、統計情報やその他の内部データへの影響も抑えることができます。
「インデックスの削除と再作成」では、手動で対象のインデックスをDROPし、その後、インデックスをCREATEする方法です。
断片化したインデックスを丸っと削除して作り直すため、作り直した後のインデックスは断片化の一切ないきれいな状態になります。
尚、行数が極端に多かったり、インデックスが付与された列が多いテーブルの場合は、前述した「再構築」より、インデックスを手動でDROPしてCREATEし直す方が圧倒的に早い場合が多いです。
後、インデックスのDROP時やCREATE時には、そのテーブルはロックされるため(DROPは一瞬ですが)、オンラインで処理はできません。
上記の両手法はそれぞれメリットデメリットがあるため、状況に合わせて適切な手法を選択する必要があります。
また、必要なインデックスが付与されていないケースでは、各テーブルの用途や列の値の特徴から、明らかにインデックスを追加したほうが良いと直感的にわかる場合もあり、それであればすぐにインデックスを付与すればよいですが、もっと根拠を持って対応しようとする場合は、そのデータベース内のコストの大きいクエリを抜き出して解析することで、インデックスを付与するべき列を調べることもできます。
他項でも記載しましたが、各RDBMSでは、データベースの状態をモニタリングするツールやコマンドが用意されています。
その機能のなかには、コストの大きい(遅いクエリとか高負荷なクエリ)クエリを抜き出してくれる機能も用意されています。
その機能を活用し、抜き出した個々のクエリ内容を解析することで、インデックスを付与するべき列を分析することが可能です。
この行為は一般的な「SQLチューニング」の一つでもあります。
Accessなど第三のアプリケーションによる原因
データベースは様々なアプリケーションやクライアントから処理要求を受け付けて、指定されたレコードを要求元に返したり、指定されたレコードの更新などを行います。
データベースを利用するアプリケーションが増えたり、システム改修を行ったわけでもなく、元々認識しているクライアント数が増加したわけでもない。
また、データベースの障害などが発生している形跡もないにもかかわらず「最近遅くなったな」と感じたら、システム管理者やDB管理者が認識していない「第三のアプリケーションやクライアント」が原因というケースもあります。
当記事における「第三のアプリケーション」の具体例としては以下です。
- AccessやExcelを用いてEUCが作成した業務アプリケーション
- Accessやその他のDB接続ツールによるデータ集計処理
- RPAなどの業務自動化ツール
昨今ではDXという言葉も多く聞かれるようになり、業務の電子化や省力化は、企業における重要な経営課題です。
また、非IT部門において、自部署で使用する業務システムを、外部のシステム開発会社や自社の情報システム部門に依頼して作ってもらうのではなく自部署で内製する、所謂「EUC(End-User Computing)」を取り入れている企業も増えています。
この「EUC」において、最も広く、且つ最も古くから利用されているツールと言えば、Microsoft Officeの製品である「Excel」と「Access」です。
Excelは多くの企業のOA事務作業で使用されており、Excelに組み込まれている「VBA」を活用することで、様々な操作や作業を自動化することができます。
また、フォームを作成することができ、簡易的な業務アプリケーションとしても利用することが可能です。
最近では機能も増えて、「Power Query」などデータベースと接続することも容易になっています。
Accessは簡易的なデータベースソフトでありながら、OracleやSQL Serverなどの外部のデータベースとも容易に接続してデータ抽出することが可能であり、様々なフォームや帳票を作成することができます。
また、マクロ機能やVBAを用いることで、データ入力や検索、表示フォームを簡単に作れたり、データベースと連携した帳票を出力することができ、本格的な業務アプリケーションを作ることも可能です。
このExcelやAccessは企業のPCに標準でインストールされている場合が多く、非IT部門であってもシステム管理者などに了承を得ることなく、自由に利用できる点でもEUCで活用しやすいポイントです。
EUC自体は企業における業務の電子化や効率化のために推進するべき取り組みだと思いますが、それはあくまで、EUCでの改善活動が「システム管理者の管理下に収まっている」場合においてです。
EUCによる活動で作成されたシステムや業務アプリケーションを、その企業の情報システム部門が管理していなかったり、存在を把握できていない場合は、社内システムの安定稼働に対するリスクや事業継続におけるリスクとなります。
データベースに関連したリスクとしては、AccessやExcelなどの非IT部門が内製した業務アプリケーションからデータベースへのリクエストの増加や、負荷の高いクエリの発行などが考えられます。
非IT部門の従業員の場合、データベースに関する技術的な知識が乏しい場合も多く、アプリケーションの実装において、例えばループ処理で不必要にデータベースの参照を繰り返したり、インデックス等が加味されていない負荷の高いSQLを発行してしまっているケースもあります。
アプリケーションが参照するデータの規模やアプリケーションの利用頻度によっては、データベース全体の負荷上昇や性能低下に繋がる場合があります。
また、そのような作りのアプリケーションでは、ロックを発生させてしまうことも多々あり、それによってロック待ちの増加やデッドロックの誘発を招く場合もあります。
データ抽出目的で実行される複雑なクエリや対象範囲が極端に広いクエリを実行した場合も、データベースの負荷を高めたり、ロックプロセスを増加させてしまう要因になり、その結果、データベース全体の速度低下を招く場合があります。
RDBに対して接続してデータ抽出を行うツールとして、昔から最も広く利用されているのはMicrosoft Accessです。
Accessでは、SQLを知らなくてもRDBに対してデータ抽出処理やデータ更新処理が行える「クエリ」という機能があり、それを利用することで、データベースの専門的な知識がなくても容易にデータ抽出などが行えます。
この機能自体は大変便利なものですが、データベースの専門的な知識がない場合は、データベースの負荷やその影響などを考慮することが難しいこともあり、全行を対象にしたクエリや、インデックス対象ではない列を条件に指定したクエリなどを実行してしまい、データベースに意図せず高い負荷を掛けてしまうことはよくあります。
また、最近ではExcelでも「PoweQuery」で容易にデータベースに接続してデータ抽出ができるようになりましたが、やはり意図せず負荷の高いクエリを高頻度で実行してしまうリスクは存在します。
尚、AccessやExcelだけではなく、他にも様々なデータベース接続ツールがあります。
また、データベースに接続してデータ集計処理に特化した「BIツール(Business Inteligence Tool)」を導入している企業もあり、データベースはデータ抽出、データ集計目的で様々なアプリケーションからアクセスされる場合があります。
このように、企業内の業務システムや業務アプリケーション以外に、データ抽出やデータ集計による処理がデータベースの負荷を高めるケースも考えられます。
企業内のOA事務作業を効率化したり自動化する際に、最近利用されることが多いのは「RPA(Robotic Process Automation)」です。
RPAでは、プログラミングの専門的な知識や経験がないひとであっても、パソコン内での作業を自動化することができます。
また、RPAはEUCの代表的なツールのひとつであり、非IT職の人が能動的に利用して、自身や自部署の業務を自動化する目的で利用されます。
適切に利用する場合は非常に便利なツールですが、RPAで自動化する作業工程のなかに、データベースを参照させる処理を含めた場合、それがデータベースの負荷を高める可能性があります。
RPAでは、一般的なプログラミングと同じように、条件分岐や繰り返し処理が作れます。
繰り返し処理では、人が手動で実行する場合と比べてもはるかに高速に処理が実行できます。
例えば、業務システムの特定の検索画面を開き、指定した検索条件を繰り返し実行し、目的の条件に合うデータが検索結果に表示されるまで処理を繰り返すといったシナリオがRPAで作られた場合、RPAはひたすらその処理を繰り返します。
そのシナリオの作り方によっては、短時間に何度も検索処理が実行されることになり、それはデータベースの負荷を高める要因となり得ます。
また、プログラミングの知識や経験がある場合、Windows標準で利用できる「PowerShell」や「VBScript」などのスクリプト言語を使用して、業務を自動化することもできますが、そのようなスクリプトを利用した場合も、人が手作業で実施するのとは比較にならない速度で処理を行わせることができるため、スクリプトで実装した自動化処理のなかで、データベースを参照させる処理が含まれていた場合は、RPAと同様にデータベースに対して負荷を高めてしまうことも考えられます。
Accessなど第三のアプリケーションが原因だった場合の対応方法
当記事の他の対応方法でも同様ですが、データベースが遅いと感じた場合は、RDBMSごとで用意されているモニタリングツールを利用することになります。
モニタリングツールでは、現在データベースにアクセスしてきているプロセスを一覧化し、プロセスの実行元のアプリケーションや実行ファイル名を表示してくれる機能も持っている場合が多いです。
そのプロセスの一覧から頻繁に発生しているプロセスや実行時間の長いプロセス、長時間ロックを掛けているプロセスを探し、そのプロセスの実行元のアプリケーションがAccessやExcelなど業務アプリケーション以外のプロセスだと確認できれば、EUCで作成したアプリケーションだったり、データ抽出やデータ集計で使用されているツールだと推測ができます。
対象のプロセスがEUCで作成した業務アプリケーションであれば、作成者と協議して、負荷を下げる改修や工夫をしてもらうような交渉が必要です。
対象のプロセスがデータ抽出やデータ集計処理であれば、データ抽出処理や集計処理内容を見直してもらうように作成者に依頼するのも必要ですが、データ抽出やデータ集計専用のデータベースを新たに作り、データ抽出や集計では、そのデータベースを参照してもらうのもひとつの方法です。
データベースを分離することで、データ抽出や集計を行うプロセスが原因となってロック待ちを起こすことはなくなり、それだけでもある程度の改善は見込めますが、可能であれば、データ抽出、データ集計専用のデータベースはメインのデータベースとは異なるサーバー上で稼働させることが望ましいです。
それができれば、データ抽出や集計処理で負荷が高めても、それにより企業内のメインのデータベースサーバーに影響を与えることはなくなります。
アプリケーションの実装方法による原因
様々なアプリケーションがデータベースに接続し、目的のレコードの検索や取得、レコードの追加や更新、削除が行われますが、そのアプリケーションがデータベースに接続して処理を行う際の、実装方法によってはデータベースの負荷を高め、データベース全体の性能を低下させる要因となる場合もあります。
例えば、一般的なアプリケーションがデータベースに接続し、条件に合うレコードの検索して一覧画面に表示させるまでの内部的な処理の例としては以下になります。
- データベースとのConnectionを確立する。
- アプリケーション側で生成したSQL文字列をデータベースに渡して実行する。
- SQLの実行結果として目的のレコード全体をデータベースから受け取る。
- 受け取ったレコード全体を一覧画面に表示する。
- データベースとのConnectionを切断する。
この流れでは、3.で受け取ったレコードを、そのまま4.で表示させています。
データベースとアプリケーション間のデータのやり取りは、2.と3.の1往復で完結しています。
この場合は問題がないのですが、例えば3.で受け取ったレコードが多くあり、個々のレコードの特定の列の値を元に、更にデータベースから別のレコードを参照する必要があった場合は以下の流れになります。
- データベースとのConnectionを確立する。
- アプリケーション側で生成したSQL文字列をデータベースに渡して実行する。
- SQLの実行結果として目的のレコード全体をデータベースから受け取る。
- ■繰り返し処理開始(レコード行数分)
- レコードのA列の値が〇〇だった場合は以下の処理を実行
- アプリケーション側でSQLを生成してSQL文字列をデータベースに渡して実行する。
- SQLの実行結果として目的のレコードをデータベースから受け取る。
- ■繰り返し処理終了
- 受け取ったレコード全体を一覧画面に表示する。
- データベースとのConnectionを切断する。
この流れでは、3.でアプリケーションが取得した全レコードに対して、4.以降で1行ずつA列の値をチェックしています。
5.の条件分岐処理で条件に合うレコードだった場合は、更に6.と7.で別のSQLを実行して、データベースから別のレコードを取得します。
3.で取得してきたすべてのレコードに対して上記の繰り返し処理を実行し、それらがすべて完了してようやく9.で画面にレコードを表示させます。
この流れの場合、最大だと、3.で取得してきたレコードの行数分の回数のやり取りがデータベースとのアプリケーション間で発生する可能性があります。
仮に、3.で取得してきたレコード数が1万行であれば、最大で1件回のSQL実行が追加されることになります。
個々のSQLの実行に1秒掛かると仮定した場合、最大で1万秒であり、分に変換すると、166分掛かる計算になります。
また、アプリケーションを利用するユーザーが1人、又は端末が1台といったことは稀であり、通常は複数人、複数台の端末で同時に利用されます。
そのような環境下で繰り返しSQLを実行することにより、データベースサーバー自体の負荷を一気に高める可能性もあります。
アプリケーションの実装において、特定の条件を満たす、又は満たさない間繰り返すという処理は一般的なものですが、その繰り返し処理のなかでSQLを実行するような実装をした場合は、アプリケーションの処理時間が極端に長くなる可能性があり、且つ、データベースの負荷を高め、データベース全体の性能低下を招く可能性があります。
上記の繰り返し処理内でSQLを実行するような実装の場合の問題点を更に以下で掘り下げます。
アプリケーションの実装において、繰り返し処理のなかでSQLを実行することの問題点としては、前述のとおりデータベース自体の負荷増加が考えられます。
また、RDBMSによっては、レコードの参照時にデフォルトで「共有ロック」を掛ける製品もあり、共有ロックが掛けられているレコードに対して、UPDATEなどの「専有ロック」を掛けることはできないため、専有ロックを掛けようとするプロセスは待たされることになります。
よって、結果的にロック待ちプロセスが増える可能性があり、それがデータベースを利用する他のアプリケーションやクライアントの応答速度低下を招き、データベース全体の負荷を増加させることに繋がります。
また、当記事の「統計情報」の項で、オプティマイザの役割として説明したSQLの最適化やコンパイルは、データベースサーバーのCPUを利用して実行する処理であり、負荷の高める要因になる行為です。
本来は後述する「キャッシュメモリー」を活用して、都度最適化やコンパイルを行わなくても済むように工夫がされていますが、キャッシュメモリーの割り当てサイズや、RDBMSの仕様によっては、上手くキャッシュメモリーを活用してくれず、高い頻度でSQLの最適化やコンパイルが行われる可能性も十分あります。
現代の一般的なアプリケーションでは、「多層アーキテクチャ」の概念で言えば、2層、又は3層の方式が主流です。
多層アーキテクチャを簡単に説明すると以下になります。
- 1層:汎用機やホスト、スタンドアロンシステムのように、DBとアプリケーションとクライアントが一体型のシステム
- 2層:所謂「サーバー&クライアントシステム」のように、DBサーバーがあり、アプリケーションをクライアントにインストールして利用するシステム
- 3層:一般的なWebシステムのように、「DBサーバー」「APサーバー(Web)」「クライアント(ブラウザ)」と構成が分離しているシステム
詳しい「多層アーキテクチャ」の解説については、以下のWikipediaのページをご一読ください。

上記の層別のアーキテクチャで言えば、1層方式はデータベースとのやり取りが一切ネットワークに流れないため、当項の問題点の対象外です。
また、3層方式の場合、DBサーバーとAPサーバー間でのデータのやり取りがメインになり、DBサーバーとAPサーバーはセグメント自体は分離していても、同一LANに配置されているケースも多く、比較的当項で記載する問題点の影響を受けづらいです。
一番顕著に影響があるのが、2層方式のアプリケーションです。
よくあるシステム構成としては、DBサーバーがデータセンター等の異なるネットワークに配置されており、各クライアントが居る拠点とはVPNを介して繋がっているような構成です。
以下のようなイメージです。
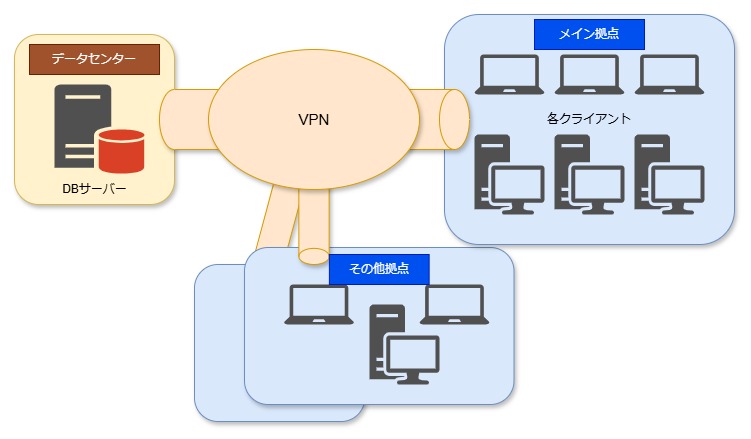
2層アーキテクチャの例
この構成の場合、各クライアントとDBサーバーはVPNを介して通信をしますが、一般的にVPNは物理的に離れたネットワーク同士を接続する場合が多く、同一LAN内のように高速な通信は望めません。
LAN内であれば最低でも1Gbpsで通信できる環境は普通ですが、VPNの場合、100Mbpsも速度がでないことはよくあります。
また、物理的な通信経路の距離も、通信の応答速度に大きく影響します。
例えば、BCP対策の一環として、データセンターを近郊の施設から、沖縄や北海道など遠方に移動した場合は、通信経路の距離による遅延が非常に大きくなります。
アプリケーションの実装方法による原因だった場合の対応方法
業務アプリケーションの特定の機能が極端に遅い、又は遅くなったという場合、まずはそのアプリケーションの対象となる処理内容を自ずと確認することになるため、比較的原因の切り分けは容易であるケースが多いとは思いますが、業務アプリケーションの特定の機能が遅いといった局所的な現象ではなく、データベース全体が遅いと感じる場合は、やはり当記事で何度か紹介している、各RDBMSごとのモニタリングツールで調べることになります。
モニタリングツールを利用することで、時間の掛かっているクエリや頻繁に何度も実行されているクエリを抜き出すことができるため、そのプロセスの実行しているSQL文の内容や、実行元のホストなどから原因となるアプリケーションやその機能を特定することもできます。
アプリケーションやその機能を特定し、特定の機能やデータベース自体を遅くしている原因が上記の「SQLを繰り返し実行している」ことや、「アプリケーションとデータベース間の通信が繰り返される」ことと判明した場合は、以下のような対応方法が考えらえます。
上記のアプリケーションの実装上の問題例において、繰り返し処理内でSQLを何度も実行せざる得ない処理にしてしまった大元の原因は、アプリケーションが最初にデータベースから目的のレコードを取得する際に、処理上必要なデータを取り切れていないことです。
最初に実行するSQLで、処理上必要なデータをすべて取得することができていれば、レコード全体を取得した後に、1行ずつ繰り返し処理を実行する必要もなくなります。
処理で必要なデータを一つのSQLで取れるように変更する場合、確実にそのSQLは複雑なものになりますが、その結果SQLの実行や、データベースサーバーとアプリケーション間の通信が1往復で完結するようになるため、間違いなく対象の機能の処理速度は早くなります。
アプリケーション側での繰り返し処理や条件分岐、追加のデータ取得などを排除し、必要なデータを一気に取得するようにSQLを見直すうえで役立ちそうなSQLの構文としては以下があります。
- CASE句:SQL内で取得した値を元に条件分岐ができます。
- UNION句:同じ構造をもつ異なる表を一つに表に結合することができます。
- サブクエリ:異なる表を特定の列同士で結合し、入れ子した一つの表として扱えます。
必要なデータを一度で取得するSQLの場合、記述も長くなりがちであり、一般的にはSQL単体のデバッグはできないものでもあるため、開発や運用の負担が増える可能性はありますが、繰り返しSQLを実行する必要がなくなるため、データベースの負荷低下やアプリケーションの応答速度改善に期待ができます。
アプリケーション側でSQLの実行も含んだ繰り返し処理が必要になる要因として、取得してきたレコードを元に、変数などを使いつつ、複雑な条件分岐やデータ加工などの処理が行う必要があるというケースもあるかと思います。
その場合、一番簡単に実装し易いのは、いったんデータベースからデータを取得した後、アプリケーション側のプログラム内で処理を記述する方法です。
但し、それだと、当項で問題視をしているような非効率な処理になってしまいます。
よって、データベースのレコードを使用して、変数を使用したり、条件分岐や繰り返し処理などの複雑な処理を行いたい場合は、「ストアドプロシージャ」を作成することをおススメします。
ストアドプロシージャの特徴や詳しい説明については、当ブログの以下の記事をご一読ください。
主要なRDBMS製品では、標準のSQL構文を独自に拡張し、複雑な条件分岐や繰り返し処理、変数を組み込んだプログラムをデータベース内に作成できます。
クライアントアプリケーション側で実装していた処理をストアドプロシージャに置き換えることで、以下のメリットがあります。
- データベース側で処理が完結するようになり、通信速度による処理遅延の影響を受けなくなる。
- ストアドプロシージャはコンパイルされた状態でデータベース内にキャッシュされ、呼び出しの度にコンパイルされることがない。
- ストアドプロシージャはオンメモリで実行されるため、処理が非常に高速。
ストアドプロシージャでは、呼び出し元に対して処理結果のみを返します。
よって、クライアントアプリケーション側で実装していた処理をストアドプロシージャへ置き換えることで、データベースとクライアントアプリケーション間の通信は、ストアドプロシージャの呼び出し時と、その結果を戻す時に発生し、1往復で完結します。
且つ、ストアドプロシージャが参照するデータベースは通常ローカルホストであり、データベースを参照する場合もネットワークに出ることはありません。
そのため、通信速度による処理の遅延が発生しません。
また、ストアドプロシージャでは、ストアドプロシージャをデータベースに登録した時点でコンパイルされ、即実行可能な状態のままでデータベースサーバーのメモリ上で保持されます。
そのため、普通のSQLのように呼び出された都度コンパイルを行うことがないため、データベースサーバーの負荷軽減にも繋がります。
また、ストアドプロシージャはデータベースサーバーのキャッシュメモリ上に保持され、実行時もメモリー内で動作します。
それにより、非常に処理も高速です。
上記のように、ストアドプロシージャに置き換えることで、処理速度やサーバー負荷の観点で大きなメリットがあります。
但し、アプリケーションの実装対象がクライアントアプリケーション内と、データベース内のストアドプロシージャとで分離され、ソースコード管理の観点では手間が増えることになり、デバッグなども面倒になるため、デメリットもありますが、データベースが遅いとお困りの場合は、クライアントアプリケーション内で実装した処理の「ストアプロシージャ化」を検討されることをおススメします。
因みに、当ブログでは、ストアププロシージャ作成に関する入門記事も掲載しています。
興味があればご一読ください。
キャッシュメモリー不足による原因
データベースサーバーを構成する主要なハードウェアの役割を簡単に説明すると以下になります。
CPUはデータベースの様々な処理で使用され、CPUの性能が不足した場合、データベース全体の処理が遅くなるため、重要な構成要素の一つです。
メモリはデータベース内の様々なデータのキャッシュで使用され、データベースの高速化において非常に重要な構成要素です。
メモリの性能が不足すると、CPUへの負担が増え、ディスクへの物理的な読み書きが増大することになり、データベース全体の処理は極端に遅くなります。
ディスクはデータベース内のデータの物理的な保管場所として使用され、データベースでは、如何にディスクに対する読み込みや書き込みを減らせるかが重要なポイントになります。
データを保管することから、十分な容量が確保されていることはもちろん重要ですが、併せてディスク自体の読み込み速度や書き込み速度も、データベース自体の性能に大きく影響します。
これらの構成要素はすべて重要なのですが、データベースのパフォーマンスチューニングの観点から最も重要だと思われるのは「メモリ」です。
上記にあるように、データベースでは、メモリ領域内でデータベース内の様々なデータを一時的に保持します。
このような使い方のメモリ領域をキャッシュメモリと呼びますが、このキャッシュメモリが不足してくると、データベースは十分なパフォーマンスを発揮できなくなります。
一般的なデータベースでは、キャッシュメモリのなかに以下のデータを一時的に保持しています。
- 実行されたSQLの実行計画やコンパイル結果
- 登録されたストアドプロシージャの実行計画やコンパイル結果
- ディスクから読み込まれたデータ
- ディスクから読み込まれたインデックスデータ
- 統計情報など最適化に必要なデータ
上記以外にも、トランザクションに関連したデータを保持したり、クエリ作成時の中間表を一時的に保持したり、表の並び替え時のワークスペースとしてもメモリを利用します。
尚、上記の各データを一時的にメモリ内に保持しますが、当然メモリ容量には上限があるため、データベースに割り当てられているメモリサイズを超えて新しいデータがキャッシュ内に保持された場合は、過去に保持したデータを破棄していきます。
一般的なRDBMSにおいて、各テーブルのデータの実体はディスク内の物理的なファイルであり、レコードの検索や更新、追加や削除の際は、最終的にその物理ファイルに対して読み込みや書き込みを行っていますが、ディスクはCPUやメモリと比較すると、データの読み書きが非常に遅く、データベースに対する個々のリクエスト毎にディスクに配置されたファイルの読み書きを行っていては、処理が追いつきません。
そこで、様々なデータを可能な限りメモリ上に載せて、ディスクの読み込みや書き込みを最小限に抑えることが、一般的なRDBMSにおける高速化のポイントです。
これは一般的なRDBMSの仕様や設計における根幹部分の基本概念です。
よって、データベースが必要とするメモリサイズの割り当てを満たせない場合は、その分ディスクへのアクセスが増加し、データベースの性能は低下することになります。
データベースが必要とするメモリサイズといっても、RDBMSによっては用途ごとにメモリ領域自体が細分化されている場合もあり、どのメモリ領域にどの程度メモリサイズを割り当てるべきかを判別するのが難しい場合もあります。
データベースに対する割当メモリサイズが足りているか否かを一番簡単に判別する方法としては、対象のデータベース全体の「バッファキャッシュヒット率」を確認する方法があります。
「バッファキャッシュ」及び「バッファキャッシュヒット率」については、以下のOracle技術ページから引用します。

データベース・バッファ・キャッシュは、バッファ・キャッシュとも呼ばれ、データベース・インスタンスのシステム・グローバル領域(SGA)内のメモリー領域です。
データファイルから読み取られるデータ・ブロックのコピーが格納されます。
バッファとは、現在使用されているデータ・ブロックまたは最近使用されたデータ・ブロックがバッファ・マネージャによって一時的にキャッシュされるメイン・メモリーのアドレスのことです。
~省略~
Oracle Databaseクライアント・プロセスで初めて特定のデータが必要になった場合は、そのデータがデータベース・バッファ・キャッシュ内で検索されます。
すでにキャッシュ内にあるデータが見つかった場合(キャッシュ・ヒット)、メモリーからそのデータを直接読み込みます。
要するに、クエリ実行時に取得したデータはバッファキャッシュというメモリ領域に一時的に保持され、以降にクエリを実行した際に、目的のデータがディスクへのアクセスではなく、バッファキャッシュから取得できた割合をバッファキャッシュヒット率と言います。
この割合が高いほど、メモリを効率的に利用できていると言えます。
このバッファキャッシュヒット率が99パーセントや98パーセントなど、100パーセントに近い値であれば問題はないのですが、80パーセントや70パーセントといった値まで下がっている場合は、ディスクアクセスが増えて、データベースのパフォーマンスはそれにより低下していると判断できます。
キャッシュメモリー不足による原因だった場合の対応方法
前述の「バッファキャッシュヒット率」が低下しているなど、キャッシュメモリが不足しているとなった場合は、まず、対象のRDBMSの設定を確認し、データベースに割り当てられているメモリサイズが適切か否かを調査します。
時々見受けられるのが、RDBMSの各パラメーターをインストール時に設定される初期値から変更せずに使い続けているケースです。
RDBMSによっては、既定値のメモリ割り当てサイズが極端に小さい場合もあり、せっかく十分なメモリをサーバーに搭載していても、肝心のデータベースがそのメモリを使用できていないといったことは結構あります。
あと、一言で「キャッシュメモリ」を言っても、RDBMSごとに、その設定値は細分化されており、細分化されている設定値の個々の最適な値は、RDBMSごとに異なります。
そこについては各RDBMSのメモリに関する公式なドキュメントをご確認ください。


尚、細分化された設定値はRDBMSによって異なるため当記事では省略しますが、データベース全体に割り当てるメモリサイズで言えば、OSが使用する分のサイズを残し、それ以外はすべてデータベースに割り当てるのが基本です。
例えば、記事執筆時点で最新のWindows Serverは「Windows Server 2025」ですが、Microsoftが案内している推奨のメモリサイズは4GBです。
よって、最低でも4GBはOSが使用するメモリサイズとして確保しておくこと必要がありますが、WindowsServerの場合、実際には4GBの割り当てだと心許ないため、できれば8GB程度は確保しておきたいところです。
仮にデータベースサーバーに搭載されている物理メモリが32GBだった場合、8GBをOS用に確保しておき、残りの24GBをすべてデータベースに割り当てるといった感じになります。
また、OSがCUIのみで使用するLinuxやUNIXであれば、OS用のメモリ割り当てをもっと減らし、データベースへの割り当てを増やすことができます。
尚、このデータベース全体にどれぐらいのメモリサイズを割り当てるべきかは、そのデータベースのデータ量や利用される用途などによってもかるため一概には言えませんが、データベースに割り当てできるメモリが多ければ多い方が、よりメモリ内にデータを多く載せることができて、ディスクアクセスを減らすことができます。
上記のようにデータベースに割り当てられているメモリサイズが適切であるにも関わらず、バッファキャッシュヒット率が低い場合は、対象のデータベースの規模やユーザー数、用途といった観点でサーバー自体に搭載されているメモリサイズが足りていない可能性があります。
よって、単純にサーバー自体に搭載するメモリサイズを増やし、その分をデータベースに更に割り当ててあげることが必要です。
バッファキャッシュヒット率が低いその他の要因として、対象のデータベースで実行されているクエリがインデックスを効果的に使用できていないといったケースも考えられます。
そのような場合は、SQLのチューニングを行いコストの低いSQLへ作り直すことで、メモリ内のインデックスで適切に使用するようになり、ディスクアクセスを減らしてキャッシュヒット率も向上します。
また、インデックスの断片化により、インデックス領域のデータ量が肥大化して、メモリ内で収まらなくなりディスクアクセスが増えてしまっているなど様々なことが考えられます。
そのような場合は、断片化したインデックスの再構築や再作成などのメンテナンスを実施することでキャッシュヒット率が改善する可能性があります。
その他の様々な考えられる原因
上記で解説した原因以外にもデータベースは様々な原因で遅くなる場合があります。
すべてを細かく解説していくと、ブログの1記事では収まらないため、上記以外に考えられる原因を以下で簡単に紹介していきます。
- ディスクI/Oの負荷による性能低下
- データ増加による性能低下
- インデックスを適切に使えていないクエリによる性能低下
- インデックスの過剰な付与による性能低下
- テーブルの正規化による性能低下
- ハードウェア性能不足による性能低下
ディスクI/Oの負荷による性能低下
データベースサーバーをクラウド上で仮想化して利用している場合は、サーバーやデータを配置しているディスクの転送速度や処理性能を意識することも少ないかと思いますが、やはりデータベースにとって、ディスクは重要なハードウェア要素の一つです。
また、物理筐体でデータベースサーバーを自前で運用しているようなケースですと、ディスクの負荷状態も常に気に掛ける必要があります。
ディスクアクセスが増える要因自体はこれまで解説してきた様々な現象に起因していると思いますが、その結果ディスクアクセスが増えることでディスクへの処理要求が滞るようになり、OSのディスクの処理待ちプロセスが増加します。
このディスクの処理要求数の指標が「Physical Disk Queue Length」です。
現在のキューの長さを確認することで、ディスクの処理が追いついていないなどの状態を知ることができます。
例えば、Windows系OSの場合、「パフォーマンスモニタ」を使用することで、現在のキューの状態をリアルタイムで確認することができます。
この値が1や2程度の小さい値であれば問題無いのですが、ディスクの処理が追いつかなくなると、この値が大きくなっていきます。
このような状態の時は、当記事で解説したようなディスクアクセスを減らす対策を取るとともに、もし複数のデータベースを同一のディスク領域で格納している場合は、負荷の大きいデータベースを異なるディスク領域に分離して、ディスクI/Oを分散させる対策も有効です。
データ増加による性能低下
単純にデータベース内のテーブルのデータ量が増加してデータベース全体の性能が低下するケースもあります。
特定のテーブルのデータ量が極端に増加し、当記事で説明したようなSQLの見直しやインデックスの見直しなどの対応しても改善できない場合は、テーブルの「パーティショニング」という機能を利用する方法があります。
テーブルのパーティショニングとは、データ量の多い巨大なテーブルをデータ範囲などで論理的に分割し、複数のパーティションに分けて管理できる機能です。
尚、実体は複数のパーティションに分割されていますが、参照する側からは一つ巨大なテーブルとして見せることができます。
また、複数に分割したパーティションを異なるディスクに配置することで、ディスクI/Oの分散にも寄与します。
よって、ログテーブルなどのように、テーブルのデータ量が増えすぎて困る場合は、パーティショニングを検討することをおススメします。
また、もっとシンプルな対応としては、単純に手動で別のテーブルを作成し、過去の古いデータは別テーブルに退避して、その分のレコードを削除する方法や、そもそも退避もせず、過去の古いデータは削除するといった方法も効果的です。
インデックスを適切に使えていないクエリによる性能低下
データベースに対して実行されるクエリ自体に問題があり、テーブルに付与されているインデックスを適切に利用できておらず、高コストなクエリが何度も実行されることでデータベース全体の負荷を高めてしまうケースもあります。
例えば、一般的なRDBMSでは、以下のような条件でWHERE句を指定した場合、対象の列にインデックスが設定されていたとしても、インデックスは使われず、全行走査になります。
- NULLを条件にする
- NOTや<>のように否定条件を使用する
- 文字列の部分一致や後方一致を条件にする
- 関数などで置き換えた値を条件にする
- 演算結果を条件にする
「IS NULL」のように、NULLを条件に指定した場合、NULLは値ではないため、通常はインデックスが効きません。
但し、RDBMSの種類や、インデックスの種類によっては、NULLを指定してもインデックスを使ってくれる場合もあります。
また、否定形の条件ではインデックスは効きません。
文字列をLIKE句などで絞り込む場合は「完全一致」または「前方一致」条件で指定をしないとインデックスは効きません。
例えば、RDBMSの組み込み関数で検索対象の列を別のデータ型に変換し、その変換結果を条件に指定するなど、関数で置き換えたり変換した値を条件に指定してもインデックスは効きません。
数値型の値を四則演算し、その結果を条件に指定する場合などもインデックスは効きません。
SQLを作る際には、目的のデータが取るという要件さえ満たせればどんな作り方でも良いというものではなく、目的のデータを取りつつ、インデックスも適切に使用した負荷の低いクエリを作るように心掛ける必要があります。
インデックスの過剰な付与による性能低下
当記事内の「インデックスの断片化」に関する解説のなかでも、インデックスを付与する必要のないデータの特徴について触れていますが、インデックスを列に設定するとクエリや早くなるという断片的な知識を元に、必要性の低い、又は必要のない列に対してもインデックスを付与しているケースも時々見受けられます。
そのようなテーブル設計では、データベースは早くなるどころか、遅くなる可能性が大いにあります。
テーブルの列にインデックスを設定することによって、最も顕著に遅くなる処理は、レコードのINSERT処理です。
一般的なインデックスの種類である「B-treeインデックス」では、二分探索木のアルゴリズムを使用しており、ルートノードを頂点として、中間ノードがあり、末端の「リーフノード」に値そのもの、または行のポインタを格納しています。
個々のノードは管理できるデータ量が決まっており、それを超えるとノードの分割処理が発生します。
それがデータベースに負荷を掛けてINSERT処理を遅くします。
レコードのINSERT時に発生するインデックスのノード分割の流れを簡単に説明します。
- ノードへのデータ追加:レコードの値をもとに、ルートノードからリーフノードまで辿り、ノードに空きがあればキーを登録します。
- ノードの空きが無くなる:ノードに空きがなく、新しいキーを格納できない場合、「ノード分割」が発生します。
- ノードの中央値の選択:ノード内のキーをソートし、中央値を選びます。この値が分割の基準になります。
- ノードの分割:元のノードを中央値を境に2つのノードへ分割します。
- 親ノードへの中央値の追加:中央値は親ノードに昇格し、親ノードに追加されます。また、親ノードも空きがない場合、さらに親ノードで分割が繰り返されます(再帰的処理)
- ルートノードの分割:ルートノードが満杯の場合、新しいルートノードが作られます。
レコードのINSERT時にはこのような処理が内部的に発生しており、インデックスを設定した列ごとにこの処理が実行されます。
よって、必要最低限の列にしかインデックスを設定していないテーブルと、様々な列にインデックスを設定しているテーブルでは、INSERT時の負荷や処理速度に大きく差がでます。
特に、数千行や数万行ぐらいのデータを一括でINSERTするような処理の場合、インデックスが多いテーブルは極端に処理が遅くなります。
また、上記の「ノード分割」時には、データの整合性を担保するために、「ラッチ(latch)」と呼ばれる下位レベルのロックが発生します。
大量のINSERTが発生した場合は、ラッチも大量に発生し、ラッチの競合が起こります。
それにより処理が待たされることになり、データベースの性能は低下します。
これらのように、インデックスは増やせば増やすほどクエリが早くなるものでもなく、計画的に必要な列にのみ設定することが必要です。
また、大量のレコードをまとめてINSERTしているようなバッチ処理の場合、INSERT処理前に対象のテーブルのインデックスをすべてDROPし、INSERT完了後に再度インデックスを作り直すといった作りに変更することで、バッチの処理速度が大幅に早くなるケースも多いです。
テーブルの正規化による性能低下
「RDB」は「Relational Database」の略称であり、関係データベースとも呼びます。
関係データベースでは、個々のデータはテーブルと呼ばれる表形式のデータで管理され、各テーブルを特定の列同士で関連付けて扱います。
管理対象のデータにおいて、繰り返し項目があればテーブルを分離し、繰り返される個々の項目を行として管理できるようにします。
また、データのキー項目に従属したデータがあれば、それもテーブルを分けて管理します。
データのキーではない項目であっても、その値に従属しているデータがあれば、それもテーブルを分けて管理します。
このように、管理対象のデータを合理的、且つ効率よく管理できるように、複数のテーブルに分離していく行為を「正規化」と呼びます。
RDBにおいて、この正規化は欠かせない概念であり、データを扱ううえで、最も基本的な技術の一つです。
この正規化が不十分な場合、データの整合性を維持したり、必要なデータをすぐに取り出すことが難しくなります。
よって、RDBを利用するにあたり、データベース内のテーブル群は適切に正規化されていることが大前提となります。
但し、データの用途や規模によっては、敢えて正規化を行わずに利用したほうが良い場合もあります。
適切に正規化をされたデータでは、分離したテーブル群を用途に合わせて結合して利用します。
逆に言えば、正規化されたテーブルの場合は、一つ一つのテーブルだけではデータとして不完全な状態と言えます。
データを完全な状態にして扱うためにはテーブル間の結合処理が必要になりますが、この結合処理自体もサーバーのCPUに負荷を与えます。
また、複数のテーブルを同時に読み込むことが必要になり、それによる負荷や遅延も発生します。
RDBにおける正規化の目的は「データの重複を排除し、データの整合性を保つこと」です。
正規化がされておらずデータの重複が発生している場合の問題は以下になります。
- データの更新時の問題:同じデータが異なる列や異なる表に存在していた場合、データの更新漏れが発生します。
- データの整合性の問題:同じデータが異なる列や異なる表に存在していた場合、データに矛盾が発生します。
- データの容量の問題:同じデータが様々な列や表に保存されることで、データ量が肥大化してストレージを不必要に消費します。
逆に言えば、個々レコードに対する更新が発生せず、レコードを更新をしないことでデータの矛盾も起こらず、ストレージ容量が十分に確保されているのであれば、正規化をしなくても良いと言えます。
敢えてテーブルに正規化を行わずに利用するケースとして多いのは、データ集計で利用されることを前提としたテーブルです。
この場合、集計で必要となるデータをすべて一つのテーブルに集約させます。
また、そのテーブルは参照専用として公開し、クライアントアプリケーションからの更新は行えないようにします。
正規化されたテーブル群のデータを元に、夜間のバッチ処理などで日々の差分をこのテーブルに追加していきます。
検索条件として指定される可能性のある列すべてにインデックスを設定します。
集計に特化した非正規化テーブルを作ることで、複数のテーブルを結合することも不要になり、複雑なSQLを実行してデータベースの負荷を高めることも無くなります。
また、それ以外にも以下のようなメリットもあります。
- 負荷の大きいクエリを実行しても業務アプリケーションの動作に影響を及ぼさない。
- データの抽出や集計においてテーブル結合が不要になり、技術的な難易度が下がる。
業務アプリケーションが参照するテーブル群に対して、データ集計目的で重いクエリを実行すると、テーブルのロックなどが発生し、業務アプリケーション側のプロセスのロック待ちを誘発することになり、トラブルが起こる可能性もありますが、参照するテーブルが分離されていれば、このようなトラブルは起こりません。
また、データベースの各テーブルを結合して目的のデータを取得する行為は、本来高度なSQLなどの知識が必要になりますが、テーブルの結合が不要な集計専用テーブルを参照するだけ必要なデータが取れるようになれば、Excelと同じようにデータベースを扱えるようになり、データ抽出やデータ集計に求められる技術の難易度を大きく下げることができます。
ハードウェア性能不足による性能低下
ファイルサーバーやメールサーバーなど、サービスを提供するサーバーは色々ありますが、それらのなかでも「データベースサーバー」は負荷が高くなりがちであり、ハードウェアにおいても非常に高い性能が求められます。
物理筐体でサーバーを運用することが主流だった時代では、サーバー稼働後にハードウェアのスペックを増強をすることが困難だったため、データベースサーバーのハードウェア構成の選定は非常に慎重に行われていました。
昨今のサーバーは仮想化が主流であり、CPUのコア数やメモリサイズ、ストレージの容量、NICの数などの構成は、すべて仮想化プラットフォーム内の管理コンソールから容易に変更ができます。
よって、データベースで思うように性能がでない場合、その原因を調査することもせず、割り当てのコア数やメモリサイズを増加したり、ストレージをより高速な(IOPSが大きい)プランに変更するなど対応で済ませてしまうこともできます。
その対応はある意味合理的とも言えますが、それではデータベースの性能を低下させている根本的な原因を突き止めることはできず、データベースの設計やパラメーター、クライアントアプリケーションなどに問題があっても改善はされません。
また、そのデータベースを運用している技術者のスキルアップにも繋がりません。
更に、性能問題が発生するたびに割り当てリソースを増加させることで、その仮想環境の利用コストが増大していく可能性もあります。
よって、データベースで性能問題が発生した場合は、本来であれば、当記事で記載した様々な調査や対応を行い、ハードウェアの増強を行わずに問題を解消させることがあるべき姿だと考えています。
サーバー構成の主流が物理から仮想に移りましたが、サーバーの性能問題が発生した場合の対策として、ハードウェアの増強(割り当てリソースの追加)は今も昔も「最終手段」です。
その前提に立ったうえで、今回の記事で解説した様々な対策を試みてもデータベースの速度が改善しない場合は、根本的にサーバーのハードウェア性能が足りていないと判断できます。
今回の記事のなかで、データベースにおける、CPUやメモリ、ディスク(ストレージ)の役割や重要性については言及してきましたが、データベースの性能に影響するその他のハードウェアとして言及しておきたいのは、NIC(Network Interface Card)です。
通常のサーバーは、IPベースのネットワークに接続して、ネットワークを介してクライアントからの処理要求を受け付けます。
その為、そのサーバーに搭載されているNICの通信帯域があまりに小さい場合は、クライアントとの通信が滞りデータベースの性能を発揮できません。
但し、現代のサーバーのNICは最低でも1Gbpsの通信帯域を持っており、クライアントとの通信のやり取りだけであれば、大規模なデータベースではない限り、NICがボトルネックになることは少ないです。
NICがボトルネックになる可能性があるNICの用途としては、データベース用のストレージとして「NFS(Network File System)」を利用している場合です。
NFSは、LinuxやUNIXのローカルストレージを外部ストレージとしてネットワーク上で公開し、他の端末のOSからネットワーク越しにストレージとしてマウントできるプロトコルです。
NFSで構築したストレージが同じネットワークに接続していれば、そのストレージを手軽に外部ストレージをマウントできるようになるため、最近ではデータベースサーバーの外部ストレージとしてもよく利用されています。

但し、データベースサーバーのストレージは、データベースの物理ファイルそのものを配置し、データベース内のデータの読み込みや書き込みで頻繁にアクセスされます。
また、そのアクセス時に発生するデータの転送量も結構なボリュームになります。
よって、サーバー側のNICが1Gbpsの帯域しか搭載されていない筐体で、NFSのストレージをデータベースサーバーの外部ストレージとして使用する場合、データベースの規模によってはNICがボトルネックになる場合があります。
NFSで外部ストレージをマウントする場合、10Gbpsの帯域があるNICを使用したり、1GbpsのNICを複数使用して論理的に一つに束ねて(リンクアグリゲーション)通信可能帯域を拡張する構成を採用することが多いです。
データベースサーバーにおけるNICの役割や重要性については上記のとおりです。
当記事でこれまで何度か説明してきたように、データベースにおいて、サーバーのCPUやメモリ、ストレージなどのハードウェアのスペックは、データベースの性能に大きく影響します。
データベースが個々のハードウェアをどのように利用して動いているのかを適切に理解し、発生している問題に合わせて最適なリソースを選定して増強することが必要です。
当ブログでは、過去にデータベースサーバーのハードウェアに関する入門記事を公開しております。
良ければ以下のリンク先もご一読ください。

但し、何度も書きますが、ハードウェアの増強はあくまで最終手段としてください。
記事のまとめ
今回の記事では、データベースが遅くなった場合に考えられる幾つかの原因を紹介し、その対応方法も解説しました。
長年データベースに関わってきていると、SQLチューニングで劇的にサーバーの負荷やアプリの応答速度が改善して感動したり、ストレージをHDDからSSDに載せ換えただけでデータベースのあらゆる挙動が速くなり、今までの苦労は何だったのかと落胆したり、色んなことがありました。
こういった経験も記事のなかに詰め込んだつもりです。
非常に長い文章になっており、読み終えること自体大変かも知れませんが、文章のなかでよくわからない言葉があれば自分で調べたりしながら、是非ご自身の知識として吸収していただけると良いかと思います。
それでは今回も読んでいただきましてありがとうございます。

