
今回の記事では、SQL Serverで初めてストアドプロシージャ(以降「ストアド」と呼称)を作成する人向けに、基本的なストアドの書き方を解説していきます。
尚、OracleやMySQL、PostgreSQLなどの、SQL Server以外のRDBMSを使用されている場合は、ストアドを作成する構文や、ストアド内の処理の記述に関する文法が異なる場合があります。
ただし、ストアド内の処理の実装方法については共通しているので、SQL Server以外のRDBMSをご利用されている場合も参考にしていただけるとは思います。
ストアドを使用するメリット・デメリット
まずは、ストアドを使用して処理を作る場合のメリットとデメリットを簡単に紹介していきます。
「すでに知っているよ」と思われる方は読み飛ばしてください。
ストアドを使用するメリット
ストアドプロシージャは、データベースサーバー上で動作し、データベースに登録されたストアドはコンパイルされた状態でメモリー上に配置されます。
クライアント側ではネットワーク越しにデータベースサーバー内のストアドを呼び出しますが、クライアントとサーバー間で発生する通信は、クライアントがサーバー側のストアドを呼び出す通信と、サーバーがストアドの実行結果を返す通信のみです。
この場合、クライアント/サーバー型システムにおいて通信がボトルネックになることはなく、また、処理はサーバー側で完結し、非常に高速に処理を実行できます。
ストアドプロシージャの大きなメリットの一つは「処理が高速」なところです。
よって、クライアント/サーバー型のシステムにおいて処理のレスポンスを改善する場合は、既存の処理をストアドで作り直すといった手法をとることも多いです。
ストアドを使用するデメリット
ストアドはデータベースに登録をしていきますが、ストアドの数が増えると、管理が非常に煩雑になります。
ストアドを利用していなければ、データベースではデータを管理し、クライアント側(アプリケーション)でデータの参照処理や更新処理を実装します。
データベースとアプリケーションは完全に分離された状態です。
ストアドを利用するようになると、データベース側でも処理が作られるようになり、クライアントのアプリケーション側以外にも処理が分散し、プログラム管理の手間が増大することになります。
管理が煩雑になり管理の手間が増えるのは、ストアドを利用する際の大きなデメリットです。
このように、メリット、デメリットがあるため、それらも考慮しながら上手く活用することが必要になります。
尚、当ブログでは、過去にデータベース全般の機能を紹介した記事を公開しており、その記事のなかでストアドについても言及しております。
より詳しいストアドの特徴などが知りたい場合は以下のリンク先もご一読ください。

今回の記事で使用している実行環境
今回の記事を作成するために使用している環境は以下のとおりです。
| SQL Server本体 | Microsoft SQL Server 2017 |
| SQL Server Management Studio(SSMS) | v18.6 |
ご利用されているSQLServerやSSMSのバージョンによっては、記事で紹介している挙動と異なる場合もあります。
ご了承ください。
当記事では、SQL Server Management Studio(以降「SSMS」と呼称)を使用して、作成方法を解説していきます。
よって、もしSSMSがお使いの端末にインストールされていなければ、以下のリンク先からダウンロードをしていただき、インストールをしておいてください。

また、データベースへの接続ができて、各テーブルの参照や更新ができるようにしておく必要があります。
具体的なストアドの作成手順と技術的な解説
当項では、実際にSSMSを使用してストアドを作成する一連の手順を紹介していきます。
また、SQL Serverのストアドを作成するには、Transact-SQLと呼ばれるMicrosoftが独自に拡張した制御構文を実装できるSQL言語を書く必要があります。
その書き方についても併せて解説していきます。
「CREATE PROCEDURE」の基本構文について
SQL Serverでストアドを作成する場合は、「CREATE PROCEDURE」ステートメントを使用します。
今回の記事では、SSMSでストアドの新規作成操作をすることで、「CREATE PROCEDURE」の記述の一部がテンプレートとして読み込まれてエディタ画面に表示されます。
それを編集していく想定で解説しますが、当項では、まず簡単に「CREATE PROCEDURE」の基本構文を解説します。
まず、CREATE PROCEDUREの基本的な構文は以下です。
CREATE PROCEDURE [ストアド名]
[@パラメーター1] [データ型] ,
[@パラメーター2] [データ型] ,
・
・
AS
BEGIN
[処理内容]
END
上記構文の処理内容部分は、Transact-SQLが使用できます。
一般的なプログラミング言語のように、条件分岐処理や繰り返し処理が実装できて、SELECTした行の値を変数に格納したり、変数の値を使用してUPDATEやINSERTなどの処理も実装できます。
また、ストアドを呼び出す際のパラメーターを設定できますが、パラメーターが不要であれば、「CREATE PROCEDURE」から「AS」の間は空白で結構です。
ストアドの作成に慣れていれば、まっさらなSQLエディタに直接「CREATE PROCEDURE」ステートメントを書いて、ストアドを作ることができますが、慣れないうちは、次項で案内するように、SSMSの機能で「CREATE PROCEDURE」の書式を読み込んで表示させてからそれを編集する手順で作成することをおススメします。
SSMSで「ストアドプロシージャ」を新規作成
SSMSの画面右側の「オブジェクトエクスプローラー」から、ストアド作成対象のデータベースを開き、「プログラミング」内の「ストアドプロシージャ」を右クリックして、「新規作成」→「ストアドプロシージャ」を選択します。
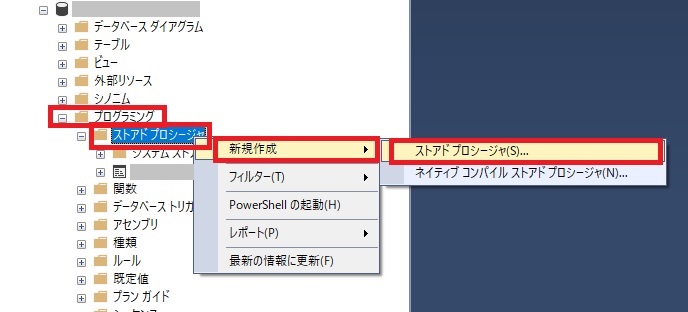
すると、画面右側に新規タブで編集画面が開きます。
上記のように「新規作成」を選択して開いた場合は、初期値としてテンプレートで用意されているテキストが入力された状態で編集画面が読み込まれます。
今回の記事では初心者向けに説明しているため、初期値のテンプレートが読み込ませるために、敢えて「オブジェクトエクスプローラー」から「新規作成」を選択する手順を紹介しています。
テンプレート読み込み時の編集画面の解説
前項の手順でストアドの新規作成を実行すると、既定では以下の内容がテンプレートから読み込まれます。
-- ================================================
-- Template generated from Template Explorer using:
-- Create Procedure (New Menu).SQL
--
-- Use the Specify Values for Template Parameters
-- command (Ctrl-Shift-M) to fill in the parameter
-- values below.
--
-- This block of comments will not be included in
-- the definition of the procedure.
-- ================================================
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: <Author,,Name>
-- Create date: <Create Date,,>
-- Description: <Description,,>
-- =============================================
CREATE PROCEDURE <Procedure_Name, sysname, ProcedureName>
-- Add the parameters for the stored procedure here
<@Param1, sysname, @p1> <Datatype_For_Param1, , int> = <Default_Value_For_Param1, , 0>,
<@Param2, sysname, @p2> <Datatype_For_Param2, , int> = <Default_Value_For_Param2, , 0>
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
-- Insert statements for procedure here
SELECT <@Param1, sysname, @p1>, <@Param2, sysname, @p2>
END
GO
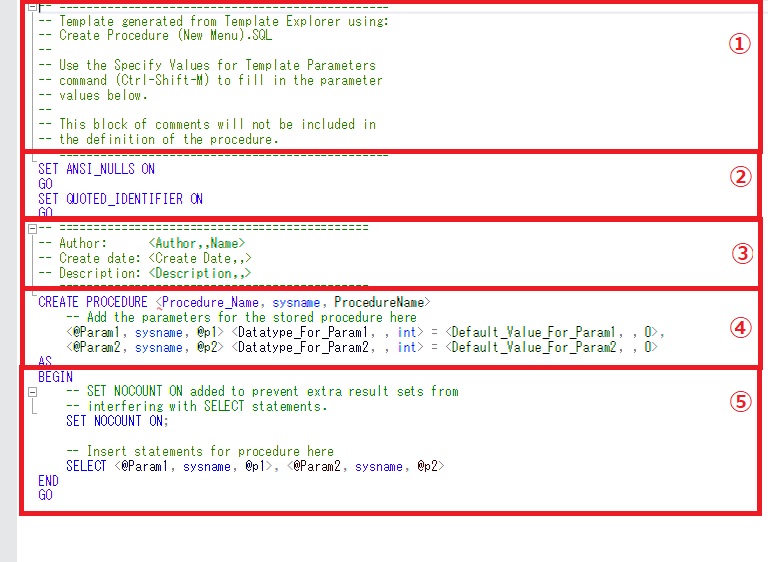
上記のスクショ内の領域ごとに番号を振り、その領域の説明をしていきます。
| 領域名 | 説明 |
|---|---|
| ①説明部分 | ただの説明なので、丸っと削除していただいて結構です。 |
| ②設定部分 | SET ANSI_NULLS: NULLに対して比較演算子を使用した場合の仕様 ONだとISO準拠 通常はONのまま SET QUOTED_IDENTIFIER: リテラル文字列を区切る引用符の仕様 ONだとISO準拠 通常はONのまま |
| ③署名部分 | このストアドの作成者や日付、説明を記載します。 必須ではないため削除してもよいですが、書いていないと後から困るので書いておきます。 |
| ④ストアド名の指定とパラメーター定義部分 | ストアドの名前を指定します。 また、実行パラメーターを必要とするストアドであれば、パラメーターもここで定義します。 |
| ⑤ストアドの処理部分 | ストアドの処理を記述します。 SET NOCOUNT: ONの場合、UPDATE文などで処理した行数を返しません。必要によって変更。 |
今回の記事で作成するストアドでは、①、③は削除します。
ストアド名とパラメーター定義
前項の④部分で、ストアド名とこのストアドで使用するパラメーターを定義していきます。
読み込まれた既定値では以下のように記述されています。
CREATE PROCEDURE <Procedure_Name, sysname, ProcedureName>
ここではストアドの名前を指定しますが、この名前は、例えば「CREATE TABLE」などで新しくテーブルを作成する場合などと同様に、スキーマ名+ストアド名を指定します。
スキーマ名を省略すると、SQL Serverにおける既定のスキーマである「dbo」配下に作成されます。
よって、ストアド名を定義する場合は以下の構文です。
CREATE PROCEDURE スキーマ名.ストアド名
後、ストアド名の命名規則については、そのプロジェクトで定義されている命名規則に準じればよいのですが、そういった命名規則がなければ自由に付けて構いません。
ただし、本来名前は、それを見ただけで機能や処理がイメージできるようなものである必要があるため、慎重に決めることをおススメします。
時々、「sp_」といった接頭辞(プレフィックス)を使用して命名しているケースも見受けられますが、「sp_」はSQL Serverのシステムデータベース内で使用しているストアドでも使われている接頭辞でもあり、使わない方が良いとされています。
※実際にはシステムデータベースで使用しているスキーマ名も重複して命名しない限り問題はないと思いますが。
当記事では、接頭辞として、「usp_」を使用していきます。
※ユーザー定義ストアドプロシージャの略称
上記を踏まえて、当記事ではストアド名を以下のように指定します。
CREATE PROCEDURE dbo.usp_test
次に、パラメーターを指定していきます。
尚、ストアドを作成する場合にパラメーターは必須の設定項目ではないため、パラメーターが必要なければパラメーターを定義する記述は省略してください。
ストアドにパラメーターを設定することで、このストアドを実行する際に、数値や文字列などの値を呼び出し元からストアドに渡すことができるようになります。
パラメーターを定義する場合は、CREATE PROCEDUREを記述した次の行から、AS BEGINまでの間の位置に記述します。
新規作成時に自動で読み込まれた行は以下のようになっています。
<@Param1, sysname, @p1> <Datatype_For_Param1, , int> = <Default_Value_For_Param1, , 0>,
<@Param2, sysname, @p2> <Datatype_For_Param2, , int> = <Default_Value_For_Param2, , 0>
このテンプレートでは分かりづらいですが、@パラメーター名+データ型で指定します。
複数パラメーターがある場合は、パラメーターごとにカンマ(,)で区切ります。
例えば、パラメーター名を「praTest」として、データ型に「nvarchar」、長さは1文字と定義する場合は以下のように指定します。
@paraTest nvarchar(1)
よって、今回の記事では、ストアド名とパラメーターの定義箇所は以下のようにします。
CREATE PROCEDURE dbo.ups_Test
@praTest nvarchar(1)
AS
BEGIN
ストアドのメイン処理の作成
当項では、ストアドのメイン処理を作成していきます。
また、併せてストアドを作成するうえで必要な知識も解説していきます。
当記事で作成するストアドの処理概要
当記事で紹介する作成例のストアドの処理概要を説明していきます。
処理の流れは以下です。
- 変数を宣言
- カーソルを宣言し格納データを定義
- カーソルの行数分ループして処理を実行
- 処理を終了
まずは、このストアド内で使用する変数を定義します。
変数を使用しないのであれば、宣言も不要です。
SQL Serverでは、「DECLARE」ステートメントを使用して変数の宣言(初期化)が行えます。
DECLAREステートメントの後ろにスペースを空けて、変数名を指定します。
尚、SQLServerでは、文字列の先頭に@を付けることで変数として扱われます。
変数名を定義し、その後ろにスペースを空けてデータ型を指定します。
また、変数に値を入れるには「SET」を使用します。
DECLARE @変数名 データ型
--変数宣言例
DECLARE @hensu int
--変数への値代入例
SET @hensu = 100
また、以下のように記述することで、宣言と同時に値を格納することもできます。
DECLARE @hensu int = 100
ストアドの実装例
まずはストアドの実装例を提示します。
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[ups_Test]
@praTest nvarchar(1)
AS
BEGIN
SET NOCOUNT ON
------------------------------------------------------
--変数宣言
------------------------------------------------------
DECLARE @TargetString nvarchar(10)
DECLARE @name nvarchar(128)
DECLARE @object_id int
--変数に値を代入します。
SET @TargetString = 'マスタ'
------------------------------------------------------
--カーソル宣言
------------------------------------------------------
--カーソルを宣言してデータを定義します。
DECLARE cur_test CURSOR LOCAL FOR
--パラメーターで渡された値を条件に「システムビュー」のsys.objectsをSELECTします。
SELECT name,object_id FROM データベース名.sys.objects WHERE type = @praTest
--カーソルを開きます。
OPEN cur_test
--カーソルの先頭行を変数に格納します。
FETCH NEXT FROM cur_test
INTO @name,@object_id
--ループ処理を開始します。
WHILE @@FETCH_STATUS = 0
BEGIN
--列nameの値に変数TargetStringで指定した文字列を含むか判定します。
IF CHARINDEX(@TargetString,@name) > 0
--テーブルTestWorkに行を追加します。
INSERT INTO dbo.TestWork VALUES (@name,@object_id)
--カーソルを移動して行を変数に格納します。
FETCH NEXT FROM cur_test
INTO @name,@object_id
END
--カーソルを閉じます。
CLOSE cur_test
END
GO
上記のサンプルは、ストアドを初めて覚えるにあたって、知っておくべき最低限の処理が実装されています。
まずは、このサンプルのような処理を自身で作れるようにしておくと良いでしょう。
ストアドのメイン処理の解説
当項では、上に提示された実装例を元に、メイン処理部分(AS BEGIN以降)の記述内容を解説していきます。
まずは17行目から変数を定義します。
今回の処理では、特定の文字列を条件にテーブル名を検索し、条件に合う行をカーソルに格納する想定であり、その特定の文字列は変数に入れておくことにします。
次に、26行目でカーソルの宣言をします。
「カーソル(CURSOR)」は、ストアドの処理内で使われるメモリ内の一時テーブルのようなものです。
「DECLARE CURSOR」ステートメントでカーソル用の変数を宣言し、「CURSOR FOR」以降でSELECT文を定義することでFETCHできるようになります。
カーソルでは1行ごとにデータを取り出すことができるため、行単位で値を判定したり処理をする場合に利用します。
構文は以下です。
DECLARE [カーソル名] CURSOR FOR [select_statement]
任意のカーソル名を定義し、CURSOR FOR以降のSELECT文でカーソルに格納します。
尚、上記の構文では、カーソルのスコープは既定値が使用されます。
このスコープの既定は通常「グローバル」です。
グローバルでは、現在のセッション以外からもカーソルを参照可能になるため、以下のようにカーソルのスコープを限定して宣言した方がよいでしょう。
DECLARE [カーソル名] CURSOR LOCAL FOR [select_statement]
「DECLARE CURSOR」ステートメントでは引数も色々あるため、詳しい解説は以下のMicrosoftのページをご参照ください。
一般的に「カーソルは遅いのであまり使わない方が良い」と言われますが、ストアドを使いこなすには必ず必要になる知識です。
当記事では、「cur_test」というカーソル名で作成します。
ご注意ください。
28行目で、システムテーブル内の「sys.objects」をSELECTします。
このシステムテーブルはSQLServer内のあらゆるオブジェクトのリストを格納しており、ユーザー定義テーブルの一覧もこちらから取得できます。
今回の例では、パラメーターで渡された「type」をWHERE句内で使用して、「sys.objects」を取得します。
31行目で、カーソルを操作可能な状態にするために「OPEN」しています。
構文は以下です。
OPEN [カーソル名]
カーソルはOPENされていないと操作が行えません。
「OPEN」についても以下のリンク先をご確認ください。
34行目で、カーソルの操作をしていきます。
カーソルの移動などは「FETCH」で行えます。
今回使用する構文は以下です。
FETCH NEXT FROM [カーソル名] INTO [変数名1],[変数名2]・・・
この構文では、カーソルの次の行に移動し、その行の列を変数1,変数2に入れています。
列の値を変数に取り出さずにカーソルの移動だけであれば、INTOは以降は不要です。
尚、当実装例ではFETCH NEXTを使用していますがNEXT部分をFIRSTにすると先頭行、LASTにすると最終行への移動になります。
FETCHの詳しい説明は以下のリンク先をご確認ください。
基本的な使い方としては、カーソルの全行に対してループを開始するまえに、まず先頭行に移動しておきます。
38行目から、カーソルを使用してループ処理を開始します。
ループ処理では「WHILE」を使用します。
構文は以下です。
WHILE [真偽値を返す繰り返し条件]
WHILEの詳しい説明は以下のリンク先にてご確認ください。
WHILEは右辺の条件がTrueの間、処理を繰り返します。
尚、当記事のサンプルでは、繰り返し条件に「@@FETCH_STATUS = 0」を指定しています。
この「@@FETCH_STATUS」は、現在開かれているカーソルに対して最後に実行したFETCHステートメントの状態を返す関数です。
この関数の戻り値は以下です。
| 戻り値 | 説明 |
|---|---|
| 0 | FETCH ステートメントは正常に実行されました。 |
| -1 | FETCH ステートメントが失敗したか、または行が結果セットに収まりません。 |
| -2 | フェッチした行がありません。 |
| -9 | カーソルはフェッチ操作を実行しません。 |
WHILE内の処理の最後の45行目で、FETCH NEXTを使用してカーソルを移動してます。
その処理結果として0が返ってきている限りは、正しく次の行を読み込めたことになるため、ループし続けます。
0以外の値が返ってきた場合は、最終行を超えたか、そもそも最初の行が存在しないと判断してループ処理を終了することになります。
「@@FETCH_STATUS」関数の詳しい説明は以下のリンク先をご確認ください。
WHILEの直下で「BEGIN – END」で囲まれたブロックを用意し、そのブロック内の処理を繰り返し実行できます。
「BEGIN – END」は処理のブロックを定義します。
WHILE以外にも、IFで条件分岐する場合の処理範囲の定義でも使用します。
「BEGIN – END」の詳しい説明は以下のリンク先をご確認ください。
WHILEのループ処理のなかの41行目で、「IF」を使用して条件に合うデータのみ別テーブルにINSERTするようにしています。
Transact-SQLにおける「IF」は、他の言語にあるIFと同様に、右辺にある条件式がTrueか否かを判定して処理を分岐します。
「IF」の詳しい説明は以下のリンク先をご確認ください。
最後にカーソルを閉じてストアドを終了しています。
構文は以下です。
CLOSE [カーソル名]
「CLOSE」の詳しい説明は以下のリンク先でご確認ください。
その他の知っておいてほしいTransact-SQLの構文など
前項のサンプルでは使用していないが、ストアドを習得していくにあたって、知っておいてほしい構文などの紹介していきます。
フロー制御系
RETURN
構文は以下です。
RETURN [integer_expression]
処理を終了させる場合に使用します。
また、引数は無くても動作しますが、引数としてint型の範囲の整数値を指定することで、ストアドの終了コードを呼び出し元のプログラムに返すことができます。
IF文で条件分岐により処理結果や、エラーが発生した場合の処理結果を終了コードにセットするような使い方をします。
BREAK
ループ処理から抜ける場合に使用します。
引数はありません。
IF-ELSEの条件分岐によって、特定の条件に当てはまる場合に、ループ処理を終わらせるといった使われ方をします。
TRY…CATCH
構文は以下です。
BEGIN TRY
エラー処理範囲
END TRY
BEGIN CATCH
エラー発生時処理
END CATCH
他のプログラミング言語でもよく見掛けるエラー処理の構文を、Transact-SQLでも利用できます。
行の更新処理でエラーが発生したらロールバックといった実装などでも使用します。
トランザクション系
BEGIN TRANSACTION
構文は以下です。
BEGIN TRANSACTION
UPDATE文
INSERT文
COMMIT TRANSACTION
トランザクションを明示的に開始する場合に使用します。
この開始位置以降の更新処理は、COMMIT 又はROLLBACK ステートメントが実行されるまで保留されます。
よって、セットで「COMMIT TRANSACTION」や「ROLLBACK TRANSACTION」も必ず使用します。
ストアドの実行方法
作成したストアドを実行する方法についても簡単に紹介しておきます。
SSMSからGUIで操作してストアドを実行
SSMSの画面操作でストアドを実行するには、SSMSの画面左側の「オブジェクトエクスプローラー」から対象のストアドを選択、右クリックして「ストアドプロシージャの実行」を選択します。
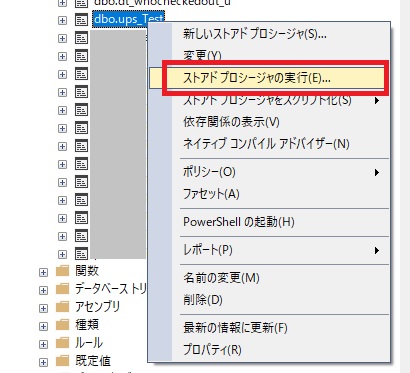
「プロシージャの実行」画面が別ウィンドウで表示されます。
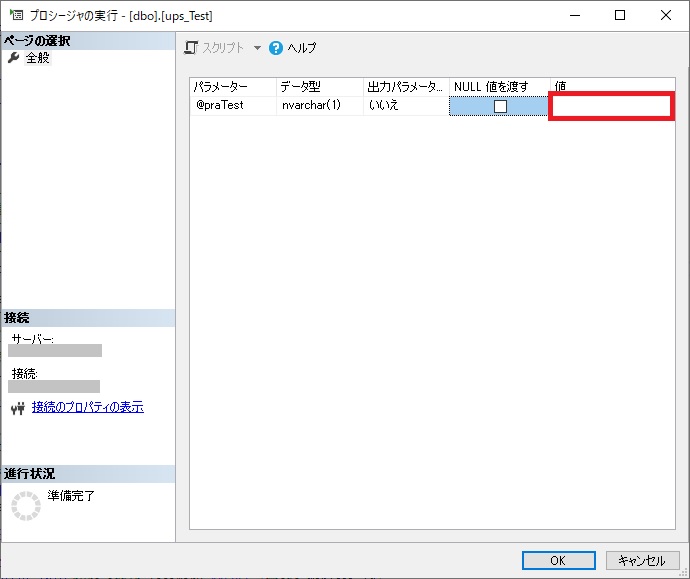
実行パラメーターが必要な場合は、画面右側のパラメーター欄の「値」に適切な値を入力し、画面下部の「OK」を押下することで実行されます。
今回の記事で提示したサンプルストアドの場合は、アルファベットの U を値に入力します。
SQLコマンドからストアドを実行
SQLを書いてCUIでストアドを実行する場合は、「EXEC(EXECUTEでも良い)」ステートメントを使用します。
構文は以下です。
EXEC [ストアド名] [パラメーター1] , [パラメーター2]
今回の記事で紹介したサンプルストアドを実行する場合は以下のSQLコマンドです。
EXEC [dbo].[ups_Test] 'U'
ADOを介して外部プログラムからストアドを実行
外部のプログラムからADOを介してストアドを実行する場合は、ADOのCommandオブジェクトを使用します。
「VBAからADOを使用してストアドプロシージャを実行する方法」については、過去に当ブログの記事で紹介しております。
良ければこちらもご参考にしてください。
最後に
今回の記事では、SQL Serverのストアドプロシージャを初めて作成する人向けに、SSMSを使用したストアドの作成方法について紹介しました。
クライアント/サーバー型のアプリケーションにおいて、各実行環境で使用しているクライアントアプリケーションが別セグメントのデータベースサーバーと通信しているケースでは、データベースへのアクセスの度にネットワークを経由することで遅延が発生し、それが大きなレスポンスの低下に繋がります。
そのような状況でお困りの場合は、クライアントアプリケーション側で実施している処理をストアドに置き換えてしまうことで、劇的なレスポンスの改善が見込めます。
機会があれば是非お試しください。
今回も読んでいただきありがとうございました。
それでは、皆さまごきげんよう。