今回の記事ではデータベース入門記事として、新米SEがテーブル設計をするうえでやってはいけないバッドノウハウを紹介していきます。
尚、当記事はRDB(リレーショナルデータベース)を覚えたての初心者を対象にしています。
業務システムの開発経験があり、ある程度の規模の商用環境での運用経験がある場合は誰もが理解しているような初歩的な内容ではありますが、テーブル設計は実際にシステムを運用して初めて問題に気付くことも多くあり、そのような経験が少ない場合は参考にしていただけるのではないかと思っています。
テーブル設計の重要性について
当項では「テーブル設計の重要性」について個人的な考えを紹介していきます。
あらゆるシステムでは裏にデータベースが存在し、ユーザーのあらゆる操作はデータベースに書き込まれていきます。
今回の記事では「あらゆるシステム」のなかでも、主に「業務系システム」で使われるようなテーブル設計を前提としてまとめていきますが、「業務系システム」においても、やはりデータベースやテーブルの設計は非常に重要です。
業務システムの開発においても、ここ近年は「コードファースト」という開発方式が増えています。
従来のシステム開発では、まず最初に、システムの要件を元にデータを格納や参照するために必要となるテーブル構成を検討して、それらのテーブルをデータベースに作成します。
そのデータベースに合わせてアプリケーションを作成(コーディング)していきます。
以前からこの言葉が存在していたかはわかりませんが「データベースファースト」とも呼べます。
「コードファースト」では、アプリケーションをコーディングしながら、そのプログラム内でデータを管理するためのクラスを作り、それらが接続先のデータベースに対して自動的にテーブルまで作ります。
コード上で定義したデータのクラスにデータベース側が自動で合わされるようになり、システム開発の最初にかっちりとしたテーブル設計をする工程が不要になり、開発中のデータの定義の変更に併せてデータベースを修正する必要も無い為、効率的なアプリケーション開発が行えます。
但し、この「コードファースト」が有効なのは小規模~中規模な業務アプリケーションであり、高い信頼性が必要とされる大規模の業務アプリケーションにおいては、今でも「データベースファースト」が主流だと思います。
※業務システム開発の現場から離れて時間が経っているので、最近の状況はあまりわかっていないのですが。
例えるなら、業務システムにおいて、データベース内のテーブル構成は「木の幹」であると言えます。
建物で例えるなら「基礎」であり「土台」とも言えます。
システムの根幹を成しており、その根幹の上にアプリケーションが構築されます。
また、アプリケーションの実装を工夫して何とか動くものができても、複雑な実装が必要になることで度々不具合を起こしたり、レスポンスや負荷の観点から性能に問題が発生することも容易に想像できます。
逆に言えば、適切に設計されたデータベース(テーブル群)があれば、上に載せるアプリケーションは少ない労力で高い品質のものが出来上がると言えます。
また、データベースは基本的にデータを蓄積して管理するための仕組みです。
そのシステムを利用しだして時間が経過するほど多くのデータを扱うことになり、減っていくことは原則的にありません。
適切に設計されていないデータベースでは、システムの開始当初は問題が無くても、利用開始から時間が経つことでシステムのレスポンスがどんどん遅くなり、不安定になります。
長々と書いてしまいましたが、上記のように、アプリケーション開発においてテーブル設計は非常に重要です。
今回の記事では、そのテーブル設計において多少なりとも参考になれば幸いです。
テーブル設計でやってはいけないポイント
当項では、テーブル設計においてやってはいけないポイントを理由も併せて紹介していきます。
尚、紹介する内容は、私が実際に関わったシステムでこれらの”ダメ”なテーブルが使われていてアプリケーションの開発や運用に苦労した実体験に基づいています。
そう、すべて実話です・・・。
主キーが設定されていないテーブルを作ってはイケナイ
RDBにおいて、テーブルには必ず「主キー」を作るものだという自身の常識から逸脱したテーブルを使用したシステムを運用した経験があります。
このテーブルを設計した名も知らない開発者は主キーの本来の意味を理解していなかったのだろうと思われます。
そのテーブルは毎日数千件のレコードがINSERTされて、頻繁に検索もされるトランザクション系テーブルです。
おそらく設計者は、アプリケーション側からそのテーブルを参照する際には必ず複数の列を条件に指定する前提で、特定のレコードを一意に選択するケースが頭になかったのだろうと予想します。
テーブルに主キーが設定されていないとどのような問題があるのでしょうか?
レコードの列には更新日時などもあり、ミリ秒まで格納できるとしても、そのミリ秒単位で重複しつつ、他の列の値も同一のレコードが複数作成されてしまった場合、そのレコードを一行だけ取得する術は無くなります。
これは結構致命的な問題です。
また、上記のように一意にレコードを指定できない問題以外にも、レコードの並び順をORDER BY句で明示的に指定しない限り、SELECTの都度取得してきたレコードの並び順も変わってしまいます。
こちらも地味に厄介です。
ただ、格納するデータの特性から、特定の列単体を主キーと指定したり、複合キーとして複数の列を指定して一意とする設計がしっくりこない場合は有り得ます。
その場合は、テーブルに主キーを作成しない選択肢を選ぶのではなく、単純なID列としてただ連番を振るだけの列を追加して、それを主キーとして使用してください。
そうしておかないと必ず後から上記のような問題にぶつかり困ることになります。
主キーが無ければINSERTなどの処理は速くなりますし。
テーブルによって同じデータでも列名が違う列を作ってはイケナイ
このケースも時々見受けられます。
例えば、日本語のカラム名でテーブルが作成されている場合で、テーブルAでは「社員コード」というカラムが存在し、テーブルBでは「社員番号」というカラムが存在する。
これらのカラムの名前は異なるが同じ値が格納されているといったケースです。
上記の例の「社員番号」程度であれば、まだ直観的に同じ値なんだろうと思えるので何とかなりますが、テーブル毎にまったく異なるカラム名だが実は同じ値を格納しているケースだと、そのテーブルを使用しているシステムの開発や運用に関わるようになった場合に非常に困ります。
その仕様を知っている人から口頭で教えてもらうか、設計書や実際のコードを読み込んでその仕様に気付かない限り、その異なるカラム名の関係を知りようがありません。
お手上げです。
ある程度の規模のシステム開発プロジェクトや、ちゃんとしたSEがいるプロジェクトでは、各テーブルで使用される列名についても予め定義します。
それはテーブル設計を行う前に実施します。
更に使用するデータ型やデータサイズも併せて定義します。
これを「ドメイン設計」と読んだりします。
名前の範囲を定義する設計です。
このような設計をテーブル設計前に実施しておかないと、上記のようにバラバラなカラム名で各テーブルは作成されてしまい、アプリケーションの実装時や運用時に混乱を招きます。
テーブルによって同じ列名なのに型が違う列を作ってはイケナイ
テーブルによって、同じカラム名が使われており、同じ値が格納されるカラムにも関わらず、データ型が統一されていないケースもとても困ります。
よくあるのは、例えばテーブルAでは「社員番号」の列のデータ型がintなどの「数値型」が使われており、テーブルBでは「社員番号」列のデータ型がvarcharなどの「文字列型」が使われているといった感じです。
格納するデータの値は確かに同じものを格納することはできますが、このようなテーブル設計では、テーブルAの社員番号とテーブルBの社員番号とで結合ができません。
一般的なSQLではINNER JOIN句やOUTER JOIN句でテーブルAとテーブルBを指定し、ONで互いの社員番号を指定するとエラーになります。
また、MS Accessのクエリでリレーションを設定しようとしても同様です。
同じデータを同じデータ型で扱うことが予めルールとして徹底されていればこのようなことは起こりません。
前項では「ドメイン設計」で各テーブルが使用する「列名」についてもテーブル設計前にしっかり定義することが必要と書きましたが、列で使用するデータ型についても、同様に「ドメイン設計」で併せて定義します。
一つの列にカンマなどで区切り複数の値を格納してはイケナイ
データベースの基礎知識における「正規化」の概念が理解できていれば、このようなデータの格納をすることはないはずですが、残念なことに時々見受けられる設計です。
例えばシステムを運用していくにあたり、とあるテーブルで扱うデータを増やすことが必要になった際に、本来であればテーブルにカラムを追加したり別のテーブルを作りそこに格納するべきですが、カラムを追加するのが面倒だったりテーブルを分割することが困難な場合に、既存のカラムに格納するデータにカンマなどの区切り文字を入れて、そのカラムに複数の値を格納させてしまうといったケースです。
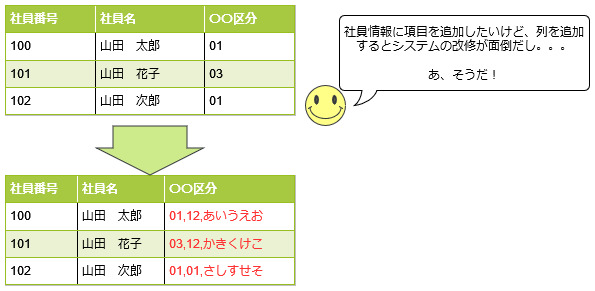
確かに対象のカラムが文字列型であれば、そのカラムの文字数やバイト数が許す範囲でどんな文字も格納できます。
それを利用すれば、カンマなどの区切り文字を付加することで、列を追加しなくても格納するデータを増やすことができますが、これは絶対にやってはいけません。
これをすることで、そのカラムを条件にデータを取得することが非常に困難になります。
仮にカンマ区切りで値を格納する場合は、そのテーブルをSELECTする際に、単純なWHERE句でレコードが取れなくなり、カンマで区切った値の何個目の値を返すような関数をデータベース内で作成して、それを介してレコードを取得することになります。
また、カラムの値の整合性の担保も困難になり、論理的な不整合が起こる要因にもなりますし、このテーブルを取得したり更新するアプリケーション側の実装も大変複雑な処理になってしまいます。
テーブル設計においてデータを容易に取り出せるように格納することも非常に大切です。
よって、もしカラムの値を区切り文字を付加して複数値を持たせたくなった場合は、必ずそのテーブルに列を追加して異なるカラムでデータを格納するようにするか、又はテーブルを別に追加して、その追加したテーブルにそれらのデータを格納するようにしましょう。
日付データを数値型や文字列型のカラムに格納してはイケナイ
日付をテーブルに格納する場合、データベースが用意している「日付型」を使用せずに、数値型や文字列型の列に日付データを格納しているケースは割と多く見受けられます。
なお、数値型であれば、20220101のような年月日の値を格納し、文字列型であれば、2022/01/01のように日付の区切り文字も含めて格納するといった使い方です。
これも適切なテーブル設計ではないので、可能な限り避けましょう。
では、何故日付データを数値型や文字列型のカラムで管理してはいけないのでしょうか?
例えば、数値型のカラムで日付を管理する場合、メリットとしては、日付の不等号による比較や抽出が容易(実際にはそう感じるだけ)な部分です。
確かにSQLでデータを取るのも更新するもの、数値だと簡単そうに思えます。
逆に、日付データを数値で扱うことのデメリットは以下です。
- 不正な日付が格納できてしまう
- 日付の加算や減算、日数の算出が面倒になる
- データを更新したり取得して表示させる際に変換が必要
やはりデメリットで一番大きいと考えるのは、「不正な日付が格納できてしまう部分」です。
本来データベースに格納する値は、論理的に整合性の取れた正確な値が格納されるべきです。
初めからテーブルの日付データを格納するカラムが日付型であれば、2022/02/31という日付はINSERTやUPDATE時にエラーになり、物理的に格納できません。
このように、日付型を使用する限り、データベース側の機能で自動でチェックして日付としての値の整合性を担保してくれるのですが、日付型以外のデータ型を指定した場合は、その日付としての論理チェックをアプリケーション側で実装することになります。
これは明らかに手間が増え、不具合を発生させる要因になります。
また、日付の演算処理でも、日付型の方が圧倒的に楽です。
例えば月を跨いだ異なる日付間の差分の日にちを取得しようとした場合、日付データが日付型を使用していれば、データベースの組み込み関数なりで容易に日数を取れますが、日付を数値で持っていた場合は、その数値を使って直接日付演算用の組み込み関数を使うことができません。
いったん数値型のデータを日付型に変換して、その変換した値を元に組み込み関数を使うといった手間が発生します。
更に、アプリケーションで表示させたり、帳票などで出力する際の日付は当然数値のまま使用することはせず、スラッシュ区切りの日付や、年月日で区切った形式の日付を使用します。
結局数値から日付フォーマットへの変換が必要になります。
だったら、データをそのまま表示できたり、軽微なフォーマット変更で出力できる方が当然便利です。
尚、数値型だけではなく、文字列型でも同様です。
よって、日付データは必ず日付型で格納するようにしてください。
BLOB型で安易にバイナリデータを格納してはイケナイ
データベースのデータ型には「BLOB(Binary Large OBject)型」と呼ばれる、バイナリデータをそのまま格納できる型があります。
「BLOB型」では画像ファイルや音声、動画ファイルなどの非テキストデータをまるっと格納できるので、適切に使用すれば大変便利です。
しかし、過去の経験則から安易に利用するのはオススメしません。
その理由としては、データベースのデータサイズが極端に肥大化するからです。
データベースで扱うデータの大半はテキストデータであり、本来それほどデータサイズを必要としません。
ただ、「BLOB型」では前述したとおり非テキストデータをそのまま格納するため、テキストデータと比較すると、個々のデータサイズはテキストデータよりも遥かに大きくなるケースが大半になります。
その場合に大変になってくるのが、「データベースのバックアップ」です。
バックアップ処理では一般的に「差分バックアップ」、「増分バックアップ」、「フルバックアップ」の3種類があります。
どのバックアップの方式を選択しようが、どこかでデータベースの全データを退避させる「フルバックアップ」は実施する必要があります。
一般的なRDBMSでは、データベースを停止することなくオンラインでバックアップ処理を行えますが、その間のデータベースのレスポンスは大きく低下します。
よって、なるべく短時間でバックアップを完了させる必要がありますが、データベースサイズが肥大化してしまうとそれも難しくなります。
また、データベースの移行作業やDR(Disaster Recovery)目的でのデータベースの転送処理などを構築しようとした場合でも、そのデータベースのサイズが肥大化してしまっている場合は、その処理が非常に困難になります。
よって、安易にBLOB型でテーブルにバイナリデータを格納することは可能な限り避けるべきです。
もし画像ファイルや音声ファイルなどのデータをデータベースで管理したい場合は、物理ファイルのままデータベースの外で保管し、データベースではそのファイルのパスやファイル名や属性情報のみを格納するようにすれば済みます。
物理ファイルで保管する場合はデータベースのバックアップとは分離され、データベースのサイズが肥大化することもないですし、物理ファイルで保管することでバックアップなどの運用も簡単になります。
ありとあらゆる列にインデックスを付与してはイケナイ
データベースを扱うようになると、「カラムにインデックスを付けるとレスポンスが速くなる」といった断片的な知識で、様々なカラムにインデックスを追加しようとする人がいますが、これは誤った知識です。
インデックスを付けることで処理が速くなる場合もあれば、効果が一切無かったり、逆に遅くなる場合も多々あります。
indexは訳すと「索引」です。
例えば書籍における「索引」では、大量のページのなかから目的のページ探し出す場合に使用します。
データベースにおいても同様で、大量のレコードから目的のレコードを効率良く探し出す場合に使用します。
効果的にインデックスを利用すれば、データベースのレスポンスは劇的に速くなります。
詳しいインデックスに関する解説は、過去に当ブログで紹介したデータベース入門記事内のインデックスの説明の項をご参照ください。

上記記事のなかでも解説していますが、カラムにインデックスを設定しても、まったく効果が無かったり、逆に更に処理が遅くなる場合もあります。
レコードの追加が発生した場合、ある一定のレコード件数ごとに、そのテーブルで使用しているインデックス領域内のデータを分割したり並び替えをします。
その処理は非常に負荷の高い処理であり、レスポンスにも影響を与えます。
尚、レコードの追加以外にも、インデックスを設定した列の値を更新する場合でも同様です。
一件ごとのレコード追加であれば、このインデックス情報の並び替え処理も人が検知できないほどの一瞬の処理ですが、追加するレコード件数が数千件や数万件などの件数になってくると、顕著にその違いが感じられるようになります。
アプリケーションの実装方法によっては、大量のレコードをまとめて追加する際には、処理の高速化を狙うために、わざわざテーブルに設定してあるインデックスを処理前に削除してからレコードの追加処理を行い、完了後にインデックスを付け直すような場合もあるぐらいです。
よって、カラムにインデックスを設定する際には、以下の条件に最低一つは適合するかを確認してから付与することをオススメします。
- 対象のカラムの値はユニークまたは値の分布が大きいこと
- 対象のカラムは多くの処理の取得条件に含まれていること
- 対象のカラムは外部キーとして他のテーブルからの結合対象になっていること
- 対象のカラムの使用するSQL文をRDBMSの解析ツールで解析しボトルネックが確認できること
「区分」や「フラグ」という名の列名を作成してはイケナイ
本来テーブルにおける列名とは、そのカラムに格納する値が容易に識別できる名前である必要があります。
ただ、残念なことに、列名を見てもそのカラムにどんな値が入っているかがわからないテーブル設計をしてしまっているケースが見受けられます。
例えば見出しにあるような、「区分」という名前のカラムだったり、「フラグ」という名前のカラムなどです。
おそらくこのテーブルを作成した本人は、そのカラムの用途は自身のなかで明白だったがために、このような名前を付けたのかも知れませんが、当然本人以外にはそのカラムにどんな値が格納されているのかわかりようがありません。
よって、列名を検討する際には、何の特徴もない安易な名前にせず、必ず「○○区分」や「○○フラグ」のように何の区分なのか、何のフラグなのかを列名でしっかりと定義しましょう。
将来の拡張に備えて予め予備カラム作ってはイケナイ
テーブルに後からカラムを追加するのは大変だと言う認識のもとに、テーブルを新しく作成する際に、将来の拡張を見越して、「区分1」「区分2」「区分3」といった目先使う予定のないカラムを最初から作ってしまう人もいますが、このケースもNGです。
この場合、前項で紹介したように、列名から格納される値が判別できなくなるため、やはり運用において混乱をきたしたり、不具合を生む原因にもなります。
そもそも、冒頭でお伝えしたように、データベースにおけるテーブル設計は建物の基礎や土台であり、非常に重要なものです。
一つ一つのカラムは、そこにどんな値を格納するかを検討した後、その値に合わせたデータ型を選定し、文字列型であれば、格納する文字数などのデータサイズの上限値を想定して、無駄がないように作成していくものです。
それでは信頼性の高いシステムは構築できません。
また、予備カラムを持たせたところでそのカラムを利用するためには、何らかのアプリケーション側の改修が必要になるケースが大半です。
だったら、やはり予備カラムを持つことはやめて、現時点の実装上必要な列だけをテーブルに作成するべきです。
最後に
今回はデータベース経験の浅い人を対象に、テーブル設計においてやってはいけない、実際に経験したいくつかの事例を紹介しました。
本来は他にも色々と「ダメなテーブル」の事例はありますが、きりがないのでこの辺までにしておきます。
今回の記事が誰かの参考になれば幸いです。
今回も長々と読んでいただきましてありがとうございました。
それでは皆さまごきげんよう!