
今回の記事では、システム開発経験の無いシステム管理者向けに、最低限これだけは知っておいてほしい、「データベースの基礎知識や機能」を紹介していきます。
尚、データベースの基礎的な知識や基本的な機能を紹介していくにあたって、どうしてもお伝えしたい内容が多く、文字数が多く一つのページでは読み辛い可能性があるため、当記事は前編と後編に分割して作成します。
データベースを知っておいたほうが良い理由
当項ては、システム管理者がデータベースを知っておいたほうが良い理由を説明していきます。
データベースはシステムの基礎
システム管理者であれば、社内のあらゆるシステムの管理をする必要がありますが、データベースとはあらゆるシステムの基盤となる仕組みです。
例えば、貴方の会社のある業務をシステム化するとなった場合、システム開発会社は、貴方のシステム化対象の業務を参考にして、まずはそのシステムで必要になる基本的な機能とその機能を実装するための大まかな画面イメージを考えます。
その後はプログラミングをするのではなく、そのシステムで必要になるデータベースのテーブルを設計します。
テーブル設計ができてから、実装するプログラムの設計をして、プログラムを作り始めます。
システムにおけるデータベースは「建築における建物の基礎」です。
その基礎のうえにアプリケーションが載ります。
基礎の施工が杜撰な場合、その上に載る建物は強度が低かったり、傾いていたりして、住心地の良い建物にはなりません。
システムでも同様なのです。
社内のユーザーにシステムを引き渡す役割であるシステム管理者は、システムの機能やデザインといった表面上の実装だけではなく、その基礎である「データベース」についても品質や設計に目を光らせる必要があります。
新しいIT技術にデータベースは必要不可欠
現在のITの世界において、世の中を便利にし社会を変えると期待されている技術がいくつかあります。
例えば以下のような技術たちです。
- 人工知能(AI)
- 機械学習/深層学習
- IoT
- ブロックチェーン
- FinTech
- VR/AR
どれも何らかのかたちでデータベースが活用されています。
例えば、「人工知能」が物事を判断するための材料の一つが、過去に学習した大量のデータです。
「機械学習」では、大量のデータを読み込ませて統計学の公式に当てはめることで、人間が気付かなかったデータ間の相関性を見つけたり、過去のデータから未来の予測をします。
「深層学習」では、大量のデータを脳のニューロンに見立てた多層的なアルゴリズムで学習させて、物事を判別させたり識別せることができます。
また、「IoT」では、生活のなかで使われるあらゆる製品がネットワークに繋がり、情報をやり取りするといった構想ですが、やり取りした情報はデータとして蓄えられて、そのデータの活用がIoTの本質です。
「ブロックチェーン」は中央集権のない新しいデータベースの仕組みであり、「FinTech」は様々な金融に関する情報をデータ化します。
「VR/AR」でも、これらの技術を支え、より活用していくにはデータベースの仕組みは不可欠です。
近年はデータベースを扱うコンピューターも高性能化し、昔では到底扱いきれなかった膨大なデータを高速に処理できるようになりました。
それにより、最近では企業の経済活動や社会で利用されるITにおいて、ビックデータを如何に有効活用するのかがとても重要です。
こういった新しいIT技術を活用していくにあたって、やはりその根幹を支える「データベース」の知識は必ず必要になります。
データベースとは
「データベース」とはそもそも何でしょうか?
広義では、あらゆるデータの塊のことを指しますが、IT業界において一般的な解釈としては、「リレーショナルデータベース(RDB)」でしょう。
また、そのRDBを動かして管理するためのソフトウェアを「RDBMS(Relational Database Management System)」と呼び、「SQL Server」や「Oracle」、「MySQL」などの製品が対象になります。
当記事では、「データベース」を「RDB」と定義して書き進めていきます。
データベース(RDB)の大まかな定義
データベース(RDB)とは、様々なデータを「レコード」と呼ばれる行単位で管理します。
そのレコードは「テーブル」と呼ばれるレコードの格納領域に保存し、必要によって、条件を指定して抽出したり、変更したり、削除します。
そのテーブルは、レコードを効率的に管理ができるように分割して作成し、用途に合わせてそれらのテーブルを結合して利用します。
何百万件、何千万件といった大量のデータを高速に扱えるように様々な技術が使われています。
人々の生活や企業活動などの様々な分野を裏で支えているとても重要な技術です。
貴方がスーパーで買い物をすれば、スーパーのレジシステム(POS)では、購買データや売上データが生成され、データベースに格納されますし、勤めている会社に出社して勤怠システムで打刻をすれば、勤怠システムのデータベースに貴方の社員番号で出勤時間のデータが記録されます。
有名なデータベース製品の紹介
当項では、一般的なデータベース製品の紹介とその製品ごとの特長を紹介していきます。
尚、特徴については、私の独自の主観や過去の利用した際の経験則で書いており、もし誤りがあったり情報が古い場合があるかも知れません。
ご了承ください。
| DB製品名 | 提供元 | 特徴 |
|---|---|---|
| Oracle Database | Oracle | RDBMSの有償製品のなかでもデファクトスタンダードの位置づけにある製品であり、最も有名なデータベース製品。 他社データベース製品と比較した場合、処理が多く過酷な環境下でも高い信頼性と処理速度が期待できるため、大規模なデータベース環境に適している。 ただ、ライセンス料などが高く、適切にサポートを受けて運用していく場合に相応の費用が掛かる。 |
| SQL Server | Microsoft | RDBMSの有償製品のなかでは、Oracleに次ぐ二番手の製品。 Oracle Databaseと比較した場合にライセンス費用が安価なため、主に小規模から中規模程度の環境で利用されるケースが多い。 また、他のMicrosoft製品との連携もしやすいのも特徴。 |
| MySQL | Oracle | 無償利用が可能なRDBMSであり、オープンソース。 現在はOracle社が保有しており、有償版を利用することでサポートを受けることも可能。 オープンソースで無償利用可能なRDBMSのなかで最も大きいシェアを持っている。 また、「LAMP(Linux・Apache・MySQL・Perl/PHP/Pythonの頭字語)」と呼ばれる、ウェブサイトを開発するためのソフトウェア群にも含まれており、Web系のシステムでは好んで利用される特徴がある。 オープンソースであり無償で利用できるから有償製品より性能は劣るといったことはなく、大規模な環境でも十分に対応可能な性能を持っている。 |
| PostgreSQL | PostgreSQL Global Development Group | 無償利用が可能なRDBMSであり、オープンソース。 現在も特定の企業ではなく、個人ベースでの開発者コミュニティによって開発や運用がされている。 日本では海外と比べてPostgreSQLのシェアが高く、MySQLに近いシェアを持っている。 |
| Microsoft Office Access | Microsoft | MicrosoftのOfficeスイートの上位バージョンに同梱されている個人向けデータベースソフト。 データベース製品は本来サーバー環境に導入して複数のユーザーが同時利用する前提の製品が多いなか、Accessはパソコンにインストールして、スタンドアローンで手軽にデータベースを利用する前提で作られている製品。 純粋なデータベースとしての利用以外にも、VBAが動作してフォームやレポート作成機能もあることから、業務アプリケーションの開発環境や実行環境として利用されることも多い。 |
上記以外にも、様々なデータベース製品がありますが、まずデータベースに関する知識を習得しようとされている人が、最初に知っておきたい有名どころのデータベース製品としては、上記の製品の名前と特徴を知っておけば十分だと思います。
データベースの基礎知識と機能
当項では、データベースを全くわからない人でも、最低限押さえておいたほうがよい基本的な機能や仕組みについて簡単に紹介していきます。
これらの機能や仕組みを知っておけば、システム開発会社のSEさんが話している内容が理解できたり、自社で運用しているシステムに対する理解も深まります。
是非参考にしてください。
テーブル
データベースを理解するうえで最も重要であり、まず知らないといけないのが「テーブル」です。
「テーブル」はデータベースにおける「データを格納するための器」です。
データベースにおけるデータとは「レコード」と呼ばれ、1行を一つのデータの塊として管理します。
データベースのデータを検索したり、追加や変更をしたり、削除する場合は常にこの「レコード単位」で処理をします。
また、テーブルでは「カラム」と呼ばれる列ごとに名前を定義して、その列ごとに格納する値の種類を設定します。
数値が入る列、文字列が入る列といったように、格納する値は予め決めておく必要があります。
また、テーブルでは、そのテーブルに格納したレコードを一意に特定するための値を格納する列に対して、「主キー属性」を設定します。
この主キー属性は、テーブル内のデータを一意に特定するために使用する機能のため、主キー属性が設定されたカラム内には重複する値を格納することはできません。
この「テーブル」と「レコード」と「カラム」、「主キー」の関係性を表したイメージが以下です。

データベースにおいて「テーブル」はレコードの入れ物。
テーブルは「カラム」毎に属性を指定して、「プライマリキー(主キー)」でレコードを一意に識別するよ。
しっかり覚えておこう!
インデックス
データベースでは、テーブルに大量のレコードを保管します。
レコードの数が100件や1000件程度なら、コンピューターの本来の能力で目的のレコードを上から順にチェックして一瞬で探し出すことができます。
この時点で既に人間が目視でデータを探すのは大変ですが、コンピューターは簡単にこなします。
では、レコード件数が100万件ではどうでしょうか?
1000万件では?、1億件では?
これぐらいのデータ件数になると、コンピューターと言えども簡単にはいきません。
テーブルのレコードを先頭の1行目から最後の行まで全てのをくまなくチェックすることを「全行走査」と呼びますが、例えば100万件のレコードを全行走査する場合は流石に一瞬で探し出すことは難しくなります。
1億件のレコード件数だった場合は、コンピューターのスペックによっては、全行走査が完了するまで数時間や1日以上掛かるかも知れません。
当然そんなに処理が遅いのであれば、膨大なデータを瞬時に処理するようなシステムでは利用できません。
データベースでは、このような大量のレコードから目的のデータを瞬時に探し出す仕組みがあります。
それが「インデックス」です。
データベースが持つ「インデックス」機能を適切に活用することで、データベースは膨大なデータを素早く検索したり適切に管理することができるようになります。
その為、非常に重要な機能です。
「インデックス」は和訳すると「目次」です。
例えば昔ながらの紙の電話帳をイメージしてください。
目的の電話番号を探すには、あいうえお順になっている目次から対象のページを絞り込んで探したり、地域別で分かれている目次から対象のページを絞り込みながら目的の電話番号を探します。
大量にあるページを先頭から1ページごとに開いて、目的の電話番号を目視で順に探していくといった方法はとりません。
データベースについても同様で、電話帳における「目次」と同じように、目的のデータを効率良く管理し、素早くそのデータにたどり着けるようにした仕組みが「インデックス」です。
インデックスの使い方
インデックスはカラムごとに指定します。
一つのカラム単独で指定するだけではなく、複数のカラムを一つのインデックスとして指定することもできます(複合インデックス)。
インデックスが指定されているカラムの値を条件にレコードを検索すると、瞬時に目的のレコードを探し出すことができます。
インデックスを指定するカラムとして望ましいのは、その列で格納する値が重複のない一意の値か、それに近い分布の値。
例えば、ID番号などの識別番号や、日付などの広範囲に分布する値などです。
逆に、インデックスに適さない、インデックスがあまり有効ではない値としては、性別といった値が2つ、又は3つ程度の分布の小さいカラムや、0と1しか使わないフラグ用のカラムなどです。
値の分布が小さいカラムにインデックスを指定しても、速度改善の効果が少ないどころか、逆に色々な処理が遅くなる可能性もあります。
よって、どんなカラムでも考え無しにインデックスを付ければ処理が速くなると云う訳ではありません。
その理由を理解するために、次項ではインデックスの仕組みを簡単に解説します。
インデックスの簡単な仕組み
データベースにおいて非常に重要な「インデックス」の仕組みについて簡単に解説していきます。
まず、一言で「インデックス」と言っても、実は色々と種類があり、その種類ごとに内部の仕様は異なり、データを素早く検索するという目的に変わりはないのですが、得意な検索、不得意な検索があります。
各種類を全て解説することは記事のボリューム的にも、私自身の能力的にも難しいため、今回の記事では、インデックスの種類として最も一般的な「B-treeインデックス」の動きを元に簡単に説明していきます。
まず、「B-tree(B木)」は「二分探索木」などの探索木構造の一つです。
詳しい「B-tree」に関する説明については以下のWikipediaの記事をご参照ください。
データベース初心者の人がインデックスに関する詳細な仕様を理解する必要はなく、大まかな仕組みを理解できていればそれで充分です。
そのため、B-treeインデックスを抽象化したイメージ図を以下で用意しました。
このイメージ図を元に解説していきます。
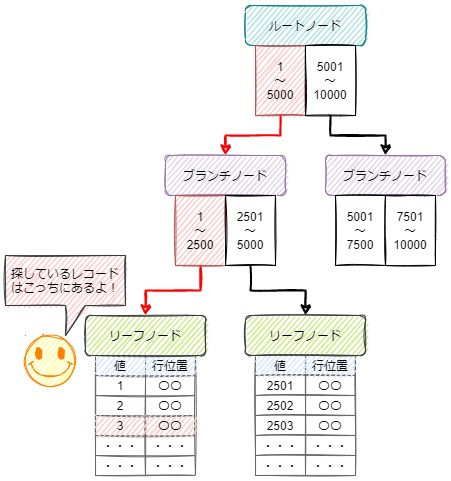
B-treeインデックスは、頂点のノードである「ルートノード」、その配下の層に「ブランチノード」、末端のノードとして「リーフノード」という様に、複数の層分けされたノードを持ちます。
ルートノードやブランチノードは、目的のデータが配下のどのノードにあるのかの情報を「二分探索」などで絞込ながら判別できるようになっています。
末端のリーフノードでは、インデックスを指定したカラムの値と、その行のポインタや内部的な行番号を格納しており、そのリーフノードを確認することで、ピンポイントで対象のデータが格納されている行を取得することができる仕組みです。
上記のイメージでは、インデックスが設定された列の値から値:3を探す際の処理の流れを表しています。
- まずルートノードを見て、値1から値5000までを管理しているブランチノードを見つける
- 次にブランチノードを見て、値1から値2500までを管理しているリーフノードを見つける
- 最後にリーフノードを見て、リーフノード内で目的の値の行位置を取得して目的のレコードに到達する
上記イメージの非常に大まかな解説としては以上です。
ブランチノードは上記のイメージ図では一つの層しかありませんが、これは本来多層化していると理解してください。
インデックスを使わずに目的のレコードを探す場合は、仮に1万件のレコードを持つテーブルであれば1万回の行参照が発生しますが、上記の様なインデックスを利用することで、ルートノードから順にノードを数回見に行くことで目的のレコードにたどり着けます。
これがインデックスです。
大量のレコードを格納しているテーブルであっても、瞬時に目的のレコードが探し出せる仕組みが理解していただけたかと思います。
上記だけを読むと、インデックスはメリットしかないため、あらゆるカラムにインデックスを設定すれば良いのでは?と考えるかも知れませんが、実はそれは間違いです。
次項ではB-treeインデックスに向かないデータや、逆に遅くなるケースを紹介します。
インデックスを設定することで遅くなるケース
当項の冒頭で、「インデックスの種類により得意不得意がある」と書きましたが、例えばB-treeインデックスの場合は、そのカラムに格納する値が広く分布している状態である必要があります。
この状態を「カーディナリティが高い」とも言います。
前項でも紹介したように、例えば「男女区分」といった値が二つか、せいぜい三つ程度しか種類が無い場合は、インデックスを設定したところで適切に機能しません。
それどころか、インデックスを設定することで、いちいちインデックスのノードを見に行く処理が加わることで、全行を上から下まで走査するより余計に遅くなる場合もあります。
その様なカーディナリティの低いカラムについては、B-treeインデックスではなく別の種類のインデックスを選定します。
また、テーブルに対してレコードの追加や更新などの処理を実行する際には、逆にインデックスが原因で処理が遅くなります。
上記イメージのブランチノードですが、このブランチノードで管理できるデータ量には上限があります。
対象のテーブルにレコードが追加されて、ノードで管理しているデータ量の上限を迎えた場合は、ノードは自動的に分割されて、そのノード内のデータも並び替えが発生し、再割り振りされます。
この処理はデータベースにとって非常に重い処理です。
レコードの追加だけではなく、更新でも同様です。
よって、大量のレコードを一斉にINSERTするような処理を実行する場合にそのテーブルに大量のインデックスを設定していると、ノードの分割や並び替えの処理が頻繁に発生し、それが処理の大きなボトルネックになります。
このノードの分割や並び替え時には、そのノードを扱う領域においてロックが発生し、それが別の処理待ちを生み、システム全体の遅延に繋がります。
よって、インデックスは適切なカラムに対して計画的に適用する必要があります。
インデックスはデータベースの高速化において欠かせない機能。
ただし、インデックスをカラムに設定することで、常に処理が速くなるわけではないため、きちんと大まかな仕組みを理解して利用しましょう!
正規化
データベースのなかでも、特にRDB(リレーショナルデータベース)では、データを管理するにあたって、データ内の従属関係を整理して、値の重複を排除し、データを複数のテーブルに分けて効率よく管理する必要があります。
このように、一定のルールに従って欠損させることなくデータを分解し、データベースで管理しやすいようにデータを分割したり、レイアウトを変形させることを「正規化」と呼びます。
データベースにおいて「正規化」は非常に重要です。
当項では、この「正規化」を簡単に解説していきます。
正規化の具体的な実施例
正規化とは本来具体的な工程が決まっています。
通常の正規化の流れとしては以下です。
↓
・第1正規化
↓
・第2正規化
↓
・第3正規化 ←一般的にはここまで
↓
・BC(ボイスコッド)正規化
↓
・第4正規化
↓
・第5正規化
・
・
・
正規化の例として、今回は一般的な請求書を発行する際のデータを正規化してみます。
例題の請求書のサンプルは以下です。
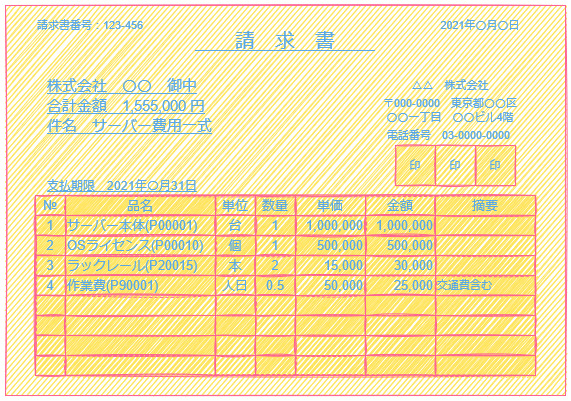
この請求書の記載内容に合わせて、必要になるテーブルを考えていきます。
まず、この請求書を元に、正規化する前の状態のデータを考えてみます。
| 請求書番号 | 発行年月日 | 取引先名 | 全体金額 | 請求書件名 | 支払期限日 | 明細番号1 | 品名コード1 | 品名1 | 単位1 | 数量1 | 単価1 | 金額1 | 摘要1 | 明細番号2 | 品名コード2 | 品名2 | 単位2 | 数量2 | 単価2 | 金額2 | 摘要2 | 明細番号3 | 品名コード3 | 品名3 | 単位3 | 数量3 | 単価3 | 金額3 | 摘要3 | 明細番号4 | 品名コード4 | 品名4 | 単位4 | 数量4 | 単価4 | 金額4 | 摘要4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 123-456 | 2021年〇月〇日 | 株式会社 〇〇 | 1555000 | サーバー費用一式 | 2021年〇月31日 | 1 | P00001 | サーバー本体 | 台 | 1 | 1000000 | 1000000 | 2 | P00010 | OSライセンス | 個 | 1 | 500000 | 500000 | 3 | P20015 | ラックレール | 本 | 2 | 15000 | 30000 | 4 | P90001 | 作業費 | 人日 | 0.5 | 50000 | 25000 | 交通費含む |
横に長くて当ページの横幅にも収まりません。
酷いデータレイアウトです。
一般的なリレーショナルデータベースは行を縦に追加していきながら利用するのが前提の仕組みであり、横のデータを拡張していくことはできません。
これではデータベースに格納できません。
まず、データベースのテーブルに格納できるようにするために、「第一正規化」を実施します。
「第一正規化」では、商品の明細が同じ行のなかで繰り返し出現しているレイアウトを排除します。
| 請求書番号(候補key) | 発行年月日 | 取引先名 | 全体金額 | 請求書件名 | 支払期限日 | 明細番号 | 品名番号 | 品名 | 単位 | 数量 | 単価 | 摘要 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 123-456 | 2021年〇月〇日 | 株式会社 〇〇 | 1555000 | サーバー費用一式 | 2021年〇月31日 | 1 | P00001 | サーバー本体 | 台 | 1 | 1000000 | |
| 123-456 | 2021年〇月〇日 | 株式会社 〇〇 | 1555000 | サーバー費用一式 | 2021年〇月31日 | 2 | P00010 | OSライセンス | 個 | 1 | 500000 | |
| 123-456 | 2021年〇月〇日 | 株式会社 〇〇 | 1555000 | サーバー費用一式 | 2021年〇月31日 | 3 | P20015 | ラックレール | 本 | 2 | 15000 | |
| 123-456 | 2021年〇月〇日 | 株式会社 〇〇 | 1555000 | サーバー費用一式 | 2021年〇月31日 | 4 | P90001 | 作業費 | 人日 | 0.5 | 50000 | 交通費含む |
「第一正規化」を行い、横に長く酷いレイアウトだったものが、いったんテーブルに格納できるレイアウトになりました。
商品ごとの横に伸びていたレイアウトは、カラムの数を固定にして商品明細毎に行を追加して商品が増えても行の追加で対応できる状態になりました。
また、商品の明細に持っていた「金額」は、本来「単価」×「数量」で導き出せる値です。
そういった値は不要な項目として、正規化処理のなかで排除していきます。
次に、「第二正規化」を実施していきます。
「第二正規化」では、「完全関数従属」「部分関数従属」を排除して別のテーブルに分割していきます。
この「関数従属」とは、そのデータの主キー的な列の値が定まるときに、それに合わせて別の列の値も決まる関係にあることを言います。
「部分関数従属」は複合キー的な列のどれかの列に対して別の列の値が従属している状態。
当請求書データでは、請求書のヘッダーデータとしての主キーは「請求書番号」です。
この「請求書番号」に従属している列を探します。
第一正規化状態の請求書データの明細行には「明細番号」が採番されており、商品ごとの明細が成り立つには「請求書番号」が必要になるため、「明細番号」は「請求書番号」に従属していると言えます。
よって、「請求書番号」と「明細番号」の二つで主キーとする明細管理用のテーブルを新設して分離していきます。
| 請求書番号(key) | 発行年月日 | 取引先名 | 全体金額 | 請求書件名 | 支払期限日 |
|---|---|---|---|---|---|
| 123-456 | 2021年〇月〇日 | 株式会社 〇〇 | 1555000 | サーバー費用一式 | 2021年〇月31日 |
| 請求書番号(key) | 明細番号(key) | 品名番号 | 品名 | 単位 | 数量 | 単価 | 摘要 |
|---|---|---|---|---|---|---|---|
| 123-456 | 1 | P00001 | サーバー本体 | 台 | 1 | 1000000 | |
| 123-456 | 2 | P00010 | OSライセンス | 個 | 1 | 500000 | |
| 123-456 | 3 | P20015 | ラックレール | 本 | 2 | 15000 | |
| 123-456 | 4 | P90001 | 作業費 | 人日 | 0.5 | 50000 | 交通費含む |
だいぶそれっぽくなってきました。
ただ、まだ「請求書ヘッダー」と「請求書明細」から分離すべき項目があります。
「第三正規化」では、「推移的関数従属」を排除していきます。
「推移的関数従属」とは、主キー的列から別の列の値が決まり、その列に従属している状態を指します。
要は、A→Bが成り立つことで、B→Cが成り立ち、A→Cにはならない状態です。
例えば、上記の「請求書明細」のデータの場合は、
「請求書番号」と「明細番号」= A に「品名番号」= B が従属しており、その「品名番号」に「品名」や「単位」や「単価」= C が推移的に従属していると言えます。
このような列も分離していきます。
第三正規化として分離した結果が以下です。
| 請求書番号(key) | 発行年月日 | 取引先コード | 全体金額 | 請求書件名 | 支払期限日 |
|---|---|---|---|---|---|
| 123-456 | 2021年〇月〇日 | T00001 | 1555000 | サーバー費用一式 | 2021年〇月31日 |
| 取引先コード(key) | 取引先名 |
|---|---|
| T00001 | 株式会社 〇〇 |
「取引先コード」を主キーとして「取引先名」を持ちます。
取引先マスタを新設したことで、取引先名に変更があった場合でも、「請求書ヘッダー」テーブルに一切の変更を加えることなく、取引先マスタ内の「取引先名」を一行修正するだけで済むようになります。
| 請求書番号(key) | 明細番号(key) | 品名番号 | 数量 | 摘要 |
|---|---|---|---|---|
| 123-456 | 1 | P00001 | 1 | |
| 123-456 | 2 | P00010 | 1 | |
| 123-456 | 3 | P20015 | 2 | |
| 123-456 | 4 | P90001 | 0.5 | 交通費含む |
よって、その「推移的関数従属」している列を「請求書明細」から排除しています。
| 品名番号(key) | 品名 | 単位 | 単価 |
|---|---|---|---|
| P00001 | サーバー本体 | 台 | 1000000 |
| P00010 | OSライセンス | 個 | 500000 |
| P20015 | ラックレール | 本 | 15000 |
| P90001 | 作業費 | 人日 | 50000 |
「品名マスタ」を新設したことで、品名や単位、単価の変更が発生した場合に、「品名マスタ」内の対象の行を一行編集するだけで済むようになりました。
最初の帳票状態の請求書データを「正規化」してテーブルに落とし込める状態になりました。
当記事ではなるべくわかりやすく解説しましたが、それでも、これまでデータベースに触れる機会の少なった人にとってはなかなか机上で理解するのは難しい概念です。
ただ、アナログな業務を元にシステムを構築する機会の多い業務系SEにとっては、データの正規化はシステム設計時に日常的に実施する作業の一つです。
慣れてしまえば無意識に非正規化されたデータを正規化できますし、第一正規化から第三正規化までを一気に実施してしまいます。
当記事のなかでも「正規化」はわりと実務経験の有無で理解のし易さはだいぶ差がでる技術です。
「正規化」の目的は、体系的に整理されていないデータをデータベースで汎用的に扱えるように整理する作業です。
適切な正規化がされていないデータベースを使用してシステムを構築すると、処理が複雑になり開発や運用が非常に大変になります。
データベースにおいて非常に大切な技術なので、しっかり頭に叩き込んでおきましょう!
SQL
データベースを扱ううえで、欠かせないのが「SQL」です。
SQLはRDBMSに対して、データの参照や更新、削除などの各種データ操作や、テーブルやインデックスの作成、ユーザーの作成といったデータベース内の各オブジェクトの定義を行うことができる、データベース専用のプログラミング言語です。
SQLはRDBMSを操作するためのプログラミング言語であり、RDBMS自体は有償、無償で様々な製品が存在しますが、基本的なSQLの構文や機能については標準化されており、異なるRDBMS間でもデータの各種操作やテーブルの作成といった一般的な処理については同じ構文で実行することができるようになっています。
ただし、RDBMSごとに製品独自の機能や仕様があり、それに合わせてSQL自体もRDBMSごとに独自の拡張がされており、基本的な操作以外のSQLの構文や機能については大きく異なっています。
SQLのコマンド種別
SQLでは、データベースに対して操作をするコマンドが大きく三つの分類に分かれます。
具体的には以下です。
| 名称 | 略称 | 内容 |
|---|---|---|
| データ定義 言語 |
DDL: data definition language |
テーブルを作成したり、インデックスを作成するといった、データ構造を定義するための命令群です。 CREATE:新しいデータベース、関係(テーブル) 、ビュー、索引、ストアドプロシージャを作成する。 DROP:既に存在するデータベース、関係(テーブル)、ビュー、索引、ストアドプロシージャを削除する。 ALTER:既に存在するデータベースオブジェクトに対する変更 TRUNCATE:関係(テーブル)からのデータの不可逆的な削除 |
| データ操作 言語 |
DML: data manipulation language |
テーブルのレコードに対して参照したり、更新や追加、削除するための命令群です。 SELECT:検索する INSERT:挿入する (新規登録する) UPDATE:更新する DELETE:削除する |
| データ制御 言語 |
DCL: data control language |
データベースの各オブジェクトに対しての権限を指定するための命令群です。 GRANT:特定のデータベース利用者に特定の作業を行う権限を与える REVOKE:特定のデータベース利用者から既に与えた権限を剥奪する |
プログラマーなどのSQL利用者の大半の主戦場は「DML」です。
前述したSELECTやUPDATEなどの命令文の配下でさらに多くのコマンドが存在し、それらを駆使して様々なデータを参照したり、更新したりします。
JavaやC#、PHPなどのプログラミング言語からデータベースに接続してSQLを実行してデータを取得したりデータを更新したりします。
一般的なIT技術者の認識では、DML=SQL であり、実際のシステム開発の現場においても、DMLという分類名称を使うことはあまりありません。
DMLとは異なり、「DDL」については、プログラマーやSQL利用者は会話のなかで「DDL」という分類名称を日常的に使用します。
IT技術者の認識では、DDL=テーブル等のCREATE文 であり、テーブルのCREATE文を催促する場合に「DDLを用意してください」といった会話をします。
DCLについては、あまりIT技術者間でもこの分類名称で呼称しあうことはない印象です。
テーブルやビューなどのデータベース内のオブジェクトに対するアクセス権を設定するための命令文が含まれる分類であり、それほど使用する機会は多くありません。
また、DMLやDCLについては、通常はSQL文を作成してコマンド実行する以外にも、RDBMS製品ごとのデータベース接続ツールが提供されており、そのツール内でGUIベースでもテーブルの作成やアクセス権の設定などの同様の操作は可能です。
ただ、IT技術者における一般的な操作としては、GUIでの操作よりSQL文を作ってDDLやDCLを実行することの方が多いです。
ではなぜGUIが使えるツールではなく、DDLやDCLなどでSQL文を作って実行するかと言えば、SQLでの操作では以下のメリットがあります。
- 予めSQL文を用意しておけば一瞬で大量のテーブル作成などが行える。
- 作成したSQLはテキストファイルとして差分管理ツールで管理ができる。
- SQL文のなかにテーブル定義などの全ての情報が含まれ可視化し易い。
- 実行したDDLやDCLを作業履歴として管理できる。
などなど。
上記のように、データベース接続ツールによるGUIでの操作よりもDDLやDCLによるSQL文を作成して実行する操作の方がメリットは多いので、可能な限りデータベースの定義作成や定義変更はDDLやDCLを作成することをおススメします。
SQLの一般的な構文
前述したSQLの分類のなかでも一番日常的に使用する「DML」で使用するSQLの構文を紹介していきます。
当記事では、あくまでシステム管理者がデータベースの基礎知識習得の一環として知っておくべき技術を紹介している観点から、SQLのなかでも非常に基礎的な部分のみに言及した内容になっています。
SQLに関するより詳しい内容については、別の技術サイトを参照するか、専門的な技術書を購入して学習されることをおススメします。
データベースのテーブルからレコードを取得(参照)する際に実行します。
指定したテーブルの全行を取得したい場合は以下のSQL文を実行します。
--全カラムを対象に全行を取得します SELECT * FROM テーブル名; --特定のカラムを対象に全行を取得します SELECT カラム1,カラム2,カラム3 FROM テーブル名;
指定したテーブルに対して、更に条件を指定してその条件に合うレコードを取得する場合のSQLは以下です。
--全カラムを対象に条件に合う行を取得します SELECT * FROM テーブル名 WHERE 条件に指定するカラム名 = 条件にする値; --特定のカラムを対象に条件に合う行を取得します SELECT カラム1,カラム2,カラム3 FROM テーブル名 WHERE 条件に指定するカラム名 = 条件にする値;
テーブルのレコードに対して特定の値で更新を掛ける際に実行します。
指定したテーブルの全行の特定のカラムを更新したい場合は以下のSQL文を実行します。
--全行のカラム1を更新します UPDATE テーブル名 SET カラム1 = 更新したい値;
指定したテーブルの条件にある行だけに更新したい場合は以下のSQL文を実行します。
--条件に合う行のカラム1を更新します UPDATE テーブル名 SET カラム1 = 更新したい値 WHERE カラム1 = 条件にする値;
テーブルのレコードを追加する際に実行します。
指定したテーブルの全カラムに値を指定してレコードを追加したい場合は以下のSQL文を実行します。
--全カラムに値を指定して追加します INSERT INTO テーブル名 VALUES (カラム1の値,カラム2の値,カラム3の値);
指定したテーブルの特定のカラムにだけ値を指定してレコードを追加したい場合は以下のSQL文を実行します。
--特定のカラムに値を指定して追加します INSERT INTO テーブル名 (カラム1,カラム2,カラム3) VALUES (カラム1の値,カラム2の値,カラム3の値);
データベースのテーブルからレコードを削除する際に実行します。
指定したテーブルの全行を削除したい場合は以下のSQL文を実行します。
--全行を削除します DELETE FROM テーブル名;
指定したテーブルに対して、更に条件を指定してその条件に合うレコードを削除する場合のSQLは以下です。
--全カラムを対象に条件に合う行を取得します DELETE FROM テーブル名 WHERE 条件に指定するカラム名 = 条件にする値;
SQL文として最もベースとなるSELECT、UPDATE、INSERT、DELETEの構文を簡単に紹介しました。
当記事では「SQLを書ける」ようにすることを目的としておらず、知識として浅く理解することを目的にしております。
データベースからデータを取得したり更新する場合には、プログラマーはこのようなSQLで処理を作成しているのだなという感じで理解してもらえれば良いかと思います。
SQLはデータベースを扱うための専用プログラミング言語です。
データベースのデータを本格的に扱う際には必ず習得が必要になる重要な技術です。
もし興味があれば習得しておいて損はありません!
【後編】について – 結合・ビュー・ストアド・トリガー・トランザクション・チューニング –
当記事では、データベース初心者向けに紹介したい知識や機能があまりに多かったため、記事内容を前編と後編に分割することにしました。

次回の「後編」では、以下の内容の知識や技術を紹介しています。
- 内部結合と外部結合
- ビュー
- ストアドプロシージャー
- トリガー
- トランザクション管理とロック
- パフォーマンスチューニング
これらの名称の内容を理解して、個々の仕組みや特徴を人に説明できるぐらいになれば、システム管理者として必要なデータベースの知識は備わったと思っていただいて良いかと思います。
それでは、今回も長々と読んでいただきましてありがとうございました。
次回の後編もよろしくお願いいたします。

