
当ブログへの流入ワードを見ているとAccessのクエリが遅くて困っている人が多そうなので、Accessのクエリの実行速度を改善するために必要となる知識や対応方法を紹介していきます。
クエリが遅い原因一覧
遅い原因として良くあるのは以下のようなものでは無いでしょうか。
- インデックスが効果的に使えていない
- 取得してきたデータ件数が膨大
- ロック待ちなど他の処理に起因する遅延
- クエリ内で見映えのためのデータ加工もやっている
この中でも「インデックスを効果的に使えていない」はデータベースを扱う上でとても重要です。先ずはこの部分を掘り下げていきましょう。
インデックスを活用して速度改善するための基礎知識
当項では、遅いクエリーを速くするためにインデックスを活用する際に必要となる知識やポイントを紹介していきます。
インデックスとはなんだ?
インデックスとは索引です。例えは紙の電話帳で電話番号を探すときに1ページから順番に探していく人は居ませんよね(今時紙の電話帳は絶滅寸前ですが)。必ず名前の頭文字や地域、業種などで目的のページにあたりをつけてから探します。
ORACLEやSQL Server、Accessなどの一般的なデータベース製品には溜め込んだデータを効率的に探す仕組みである「インデックス」が使用できます。
インデックスには幾つか種類があり、種類によってはテーブル毎に一つしか作れなかったり、何個でも複数作れるものもあります。
また、インデックスの内部仕様も様々で、内部的にデータを綺麗に並べて探しやすくしてあったり、データの値ごとに位置情報を保管し、目的のデータにピンポイントでアクセス出来るようになっていたりします。
インデックスが有効に使えていないデータ検索とは、テーブルのデータの全行を1件ずつ見ながら目的の条件に合うデータかを判別して取得するという意味であり、データが増えれば増えるほど遅くなります。
そして、クエリが遅い原因の多くも、このインデックスが有効に利用出来ていない可能性が高いです。
リンク先テーブルのインデックス確認方法
今回はSQLServer等のデータベースとリンクテーブルで接続して、クエリを実行している想定です。よって、まずはアクセス先であるリンク先テーブルのインデックスがどうなっているのかを確認する必要があります。
手順1 リンクテーブルのデザインビューを表示
Accessを開き、画面左側のオブジェクトの一覧からインデックスを確認したいリンクテーブル名を右クリックして「デザインビュー」を開きます。
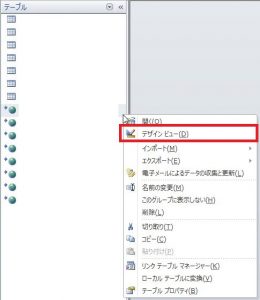
手順2 デザインビュー内の列を選択
どのフィールドでも良いのでデザインビュー内で列をクリックして選択します。

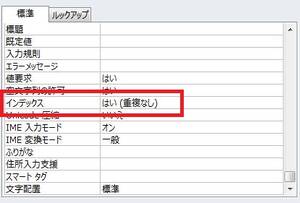
手順3 画面下部の「インデックス」を確認
項目名「インデックス」が「いいえ」になっているフィールドはインデックスが設定されていません。「はい」になっているフィールドはインデックスが設定されているので、対象のフィールドを有効に参照することで、クエリの速度を改善することが出来ます。
インデックスの使い方
クエリの作成するにあたってインデックスを効かせるようにするには、特別な操作や設定は不要で、検索や絞りこみ条件にインデックスが設定されているフィールドを使用するだけです。
そうすると、後はデータベース側で勝手にインデックスを使用してデータの検索や絞りこみを行います。
例えば顧客マスタから「山田 太郎」というデータを探す場合、氏名のフィールドにインデックスが設定されていれば、クエリの検索条件の指定箇所に”山田 太郎”と指定してあげることで、データベース側で顧客マスタの全行の氏名を見て対象のデータを探すのではなく、インデックスだけを見て条件に合うデータを効率的に探します。
インデックスが使われないダメな検索
この項がクエリを遅くしている原因と関連性があるので重要です。
インデックスが設定されているフィールドを検索条件に指定すれば、データベースは必ずインデックスを使った効率的な検索をしてくれる訳ではなく、条件の指定の仕方によっては、インデックスを使ってくれない場合があります。この項ではインデックスが使われない検索例を提示します。
ケース1 文字列を部分一致や後方一致で指定している
例えば氏名のフィールドで、Like “*太郎*” とか Like “*太郎” といった条件で検索条件を指定するのが部分一致、後方一致検索です。
インデックスで管理するデータでは、文字列の場合は先頭の文字を見るので、先頭の文字が確定出来ない検索条件ではインデックスは使われません。
あまり後方一致は使わないかもしれませんが、部分一致は比較的必要になるケースも多いかと思います。
ただそれよりは速度が大きく犠牲になるため、可能な限り Like “山田*” といった感じの前方一致に切り替えましょう。
前方一致ならインデックスは効きます。
ケース2 否定系の条件検索
否定系とは、 Not や <> を条件に使い、「何々を含まない」「何々以外」という条件指定の仕方です。この場合もインデックスは使われません。
ケース3 Nullを条件にした検索
IS NULL を条件に指定してデータを取得する場合もあるかと思いますが、Nullは本来値では無い為、インデックスにも格納できません。
よって、Nullを条件にした検索でもインデックスは使用されません。
もし可能であれば、参照先のテーブルのNull値を一括で別の値に更新し、Nullではなく、Nullを置き換えた値を指定して検索出来ればインデックスが効くようになります。
※ただし、昔はこの認識で合っていましたが、今のデータベースは効くみたいです。
他サイト様の検証結果のリンク
ケース4 検索対象のフィールドの値に対して関数で変換したり演算した結果を条件にした検索
文章で書くと分かり辛いですが、例えば「顧客マスタ」内に氏名のフィールドとは別で、「氏名カナ」という氏名のカタカナの文字列を格納するフィールドがあるとします。
その氏名カナのフィールドに対して、クエリで以下の様に関数を噛ませることでひらがなに変換できます。
氏名ひらがな:StrConv([氏名カナ],32)
このフィールドに対して、”やまだ たろう” と検索条件を指定した場合はインデックスが効きません。
インデックスはそのデータの値のまま探すためにあるので、その値を変換した結果を検索条件に指定しても、変換後の値ではインデックスの索引情報は作られていない為、インデックスも当然効きません。
ケース5 値の分布が小さいフィールドにインデックスが設定されている
これは厳密に言えばインデックスは使われているが、使われることで逆に遅くなるパターンです。
データベースに詳しくないシステム管理者が、取り敢えずどんな列でもインデックスを設定すればデータベースが早くなるといった間違った知識を付けたがために、値の分布が小さい、例えば男女の区分やフラグなどの列にもインデックスを設定しているケースが時々見受けられます。
ただ、例えば男女の区分であれば全データで2種類、最近はLGBTも取りざたされて「その他」なども入れてせいぜい3種類でしょうか。
インデックスでは、対象のデータのテーブル上の位置を格納しており、ID番号の様なユニーク(一意)の値だったり、氏名の様に同一値の比較的少ない値を管理するには適していますが、値のパターンが少ない場合は、一件一件インデックスで位置情報を取得してからデータを取得するより、テーブルの先頭行から順にデータを照合して条件に合うかを判断した方が早い場合もあります。
電話帳の例で言えば、個人宅と法人のだけの索引があって、電話番号や名前の順番もバラバラで登録されている電話帳があっても、その索引は役に立たず、結局一ページ目から順に探すことになるかと思います。
インデックスは万能な魔法の技術ではないのです。
インデックスが使われない主なケースは以上です。
クエリでデータ抽出をするにあたって、必ずデータの取得条件は設定しているかと思います。
異常に時間が掛かるクエリでは、上記のダメな条件をしていないか、一度チェックしてみては如何でしょうか?
遅いクエリの原因を調査するコツ
また、クエリが遅い原因を調査する場合ですが、私の場合は以下の様な検証を行って、どこに原因があるのかを調査しています。
- 他テーブルや他クエリと結合しているクエリの場合は、結合を一つずつ外して再実行をし、どの結合が遅延の原因になっているかを突き止める。
- 検索条件を一つずつ外して実行し、遅延の原因になっている検索条件を突き止める。
- 並び替えが設定されていれば並び替えも外して速度が改善されるか試してみる。
上記の様な検証をすることで、大体原因は見つかります。
原因が見つかれば、その処理が本当に必要かを精査し、必要であれば他の方法に置き換えが出来るかを試し、また、その処理がデータを集計した結果の表としての見栄えを良くする為の内容であれば、Excelなどに素のデータを吐き出して、表作成はExcelに任せるというのも手だと思います。
尚、以前にリンクテーブルの仕様によるクエリの遅さを解説しましたが、今回のインデックスを有効に使用してクエリをチューニングすることで、リンクテーブル越しでのデータベースへのアクセスでも十分な速度を出すことは出来ます。
↓以前の記事

今回の記事で皆さんが作られたクエリが少しでも早くなれば幸いです。
今回も読んでいただきましてありがとうございました。

